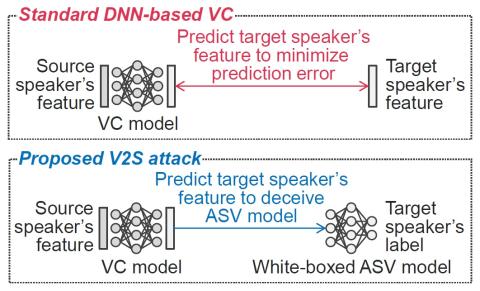
В этой статье представлена новая атака на имитацию голоса с использованием преобразования голоса. Регистрация личных голосов для автоматической проверки говорящего (ASV) предлагает естественные и гибкие системы биометрической аутентификации. В основном, системы ASV не включают голосовые данные пользователей. Однако, если система ASV неожиданно обнаруживается и взламывается злоумышленником, существует риск того, что злоумышленник будет использовать методы преобразования голоса для воспроизведения голосов зарегистрированных пользователей. Мы называем это атакой от проверки к синтезу (V2S)" и предлагаем обучение преобразованию голоса с использованием моделей ASV и предварительно обученного автоматического распознавания речи (ASR) без использования голосовых данных целевого говорящего. Модель преобразования голоса воспроизводит индивидуальность целевого говорящего, обманывая модель ASV, и восстанавливает фонетические свойства вводимого голоса путем сопоставления фонетических апостериограмм, предсказанных моделью ASR. В ходе экспериментальной оценки сравниваются преобразованные голоса между предложенным методом, который не использует голосовые данные целевого диктора, и стандартным преобразованием голоса, в котором используются эти данные. Результаты эксперимента демонстрируют, что предложенный метод работает сравнимо с существующими методами преобразования голоса, которые обучались с использованием очень небольшого количества параллельных голосовых данных.
Вывод
В этой статье представлена новая атака на имитацию голоса с использованием преобразования голоса, получившая название атаки с верификацией в синтез (V2S). Модель преобразования голоса была обучена обманывать модель автоматической проверки диктора (ASV) для воспроизведения индивидуальности целевого диктора и восстанавливать фонетические свойства вводимого голоса с помощью предварительно обученной модели автоматического распознавания речи (ASR). Результаты экспериментов показали, что предложенная атака V2S может синтезировать голос, который обладает естественностью и индивидуальностью говорящего, сравнимой с существующим параллельным преобразованием голоса с очень небольшим количеством обучающих данных. В будущей работе мы оценим атаку V2S, которая использует предварительно сохраненные голосовые данные говорящего, и исследуем зависимость входного диктора от нашего метода.