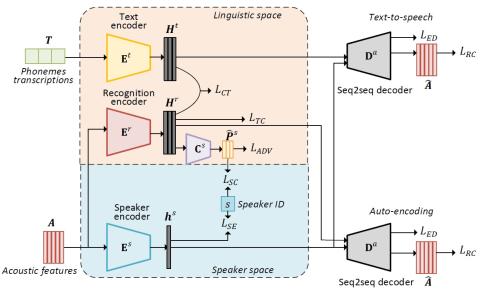
В этой статье представлен метод преобразования голоса из последовательности в последовательность (seq2seq) с использованием непараллельных обучающих данных. В этом методе из акустических характеристик извлекаются неразборчивые лингвистические представления и представления говорящего, и преобразование голоса достигается путем сохранения лингвистических представлений исходных высказываний при замене представлений говорящего на целевые. Наша модель построена в рамках нейронных сетей кодирования-декодирования. Кодировщик распознавания предназначен для изучения неразборчивых лингвистических представлений с помощью двух стратегий. Во-первых, вводятся фонемные транскрипции обучающих данных, чтобы обеспечить ссылки для использования в лингвистических представлениях аудиосигналов. Во-вторых, используется стратегия состязательного обучения для дальнейшего удаления информации о говорящем из лингвистических представлений. В то же время, представления о говорящем извлекаются из аудиосигналов с помощью кодера динамиков. Параметры модели оцениваются путем двухэтапного обучения, включающего этап предварительной подготовки с использованием набора данных для нескольких говорящих и этап точной настройки с использованием набора данных конкретной пары преобразований. Поскольку как кодер распознавания, так и декодер для восстановления акустических характеристик являются нейронными сетями seq2seq, в предлагаемом нами методе нет ограничений на выравнивание кадров и покадровое преобразование. Результаты экспериментов показали, что наш метод обеспечивает более высокое сходство и естественность, чем лучший метод непараллельного преобразования голоса в конкурсе Voice Conversion Challenge 2018. Кроме того, эффективность предложенного нами метода была сопоставима с современным методом параллельного преобразования голоса seq2seq.
Вывод
В этой статье предлагается непараллельный метод преобразования речевых сигналов из последовательности в последовательность путем изучения разрозненных лингвистических представлений и представлений говорящего. Вся модель построена в рамках нейронных сетей кодер-декодер. Для получения четких лингвистических представлений используются стратегии ввода текста и состязательного обучения. Параметры модели предварительно обрабатываются на наборе данных для нескольких говорящих, а затем настраиваются на основе данных конкретной пары преобразований. Результаты экспериментов показали, что предложенный нами метод превзошел метод непараллельного преобразования голоса, который занял первое место в конкурсе Voice Conversion Challenge 2018. Эффективность предложенного нами метода была близка к современному методу параллельного преобразования голоса на основе seq2seq. Исследования по абляции подтвердили эффективность состязательного обучения с использованием текстового ввода и предварительной подготовки модели в предлагаемом нами методе. Исследование методов однократного или многократного преобразования голоса путем улучшения прогнозирования представлений говорящего в предлагаемом нами методе будет нашей будущей работой.