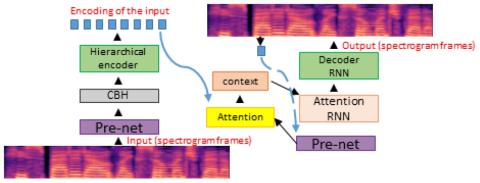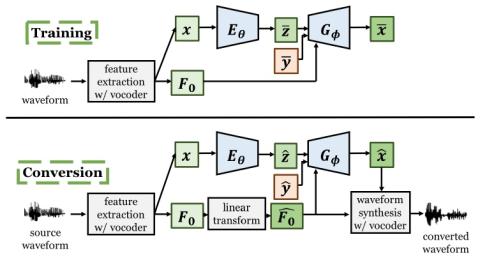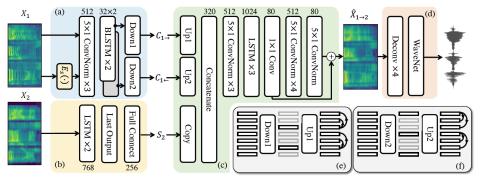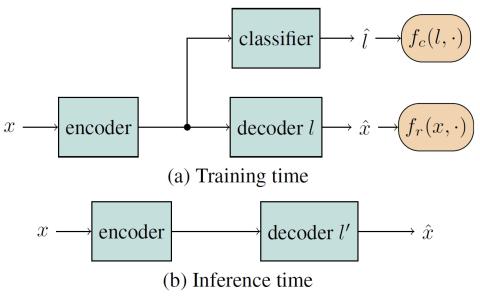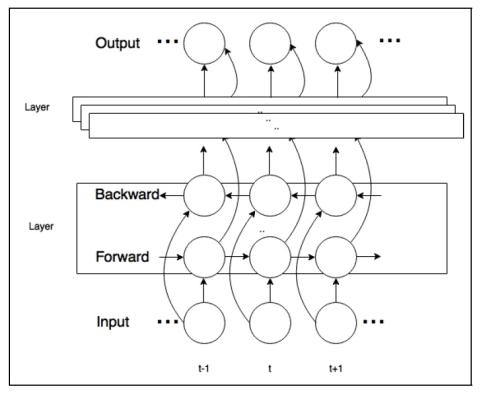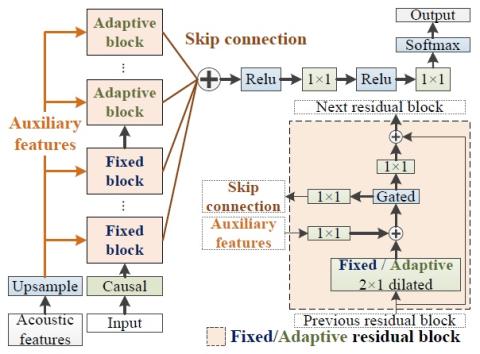
Статистическое преобразование голоса с помощью квазипериодического вокодера WaveNet
В этой статье мы исследуем эффективность квазипериодического вокодера WaveNet (QPNet) в сочетании с методом статистического спектрального преобразования для задачи преобразования голоса. Вокодер WaveNet (WN) применяется в качестве модуля генерации сигналов во многих различных системах преобразования голоса и обеспечивает значительное улучшение по сравнению с обычными вокодерами. Однако из-за фиксированной расширенной свертки и общей сетевой архитектуры вокодер WN не обладает достаточной устойчивостью к невидимым функциям ввода и часто требует большого размера сети для достижения приемлемого ка...