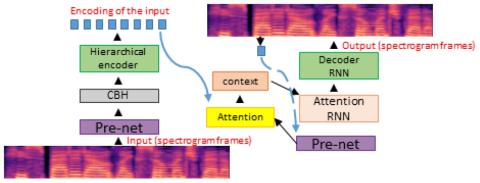
Мы представляем решение для преобразования голоса с использованием рекуррентного моделирования последовательности в последовательность для DNN. Наше решение использует последние достижения в области моделирования на основе внимания в области нейронного машинного перевода (NMT), преобразования текста в речь (TTS) и автоматического распознавания речи (ASR). Проблема заключается в параллельном преобразовании между голосами при наличии аудиопар. В нашей архитектуре seq2seq используется иерархический кодер для суммирования входных аудиокадров. Что касается декодера, мы используем архитектуру, основанную на внимании, которая использовалась в последних работах TTS. Поскольку для обучения DNN не хватает больших баз данных для преобразования голоса с несколькими дикторами, мы прибегаем к обучению сети с использованием большого набора данных для одного диктора в качестве автоэнкодера. Затем это адаптируется к меньшим наборам данных для преобразования голоса с несколькими дикторами, доступным для преобразования голоса. В отличие от других программ преобразования голоса, использующих F0, длительность и лингвистические характеристики, наша система использует mel-спектрограммы в качестве звукового представления. Выходные mel-кадры преобразуются обратно в аудио с помощью вокодера WaveNet.
Выводы
В этой работе мы продемонстрировали способ преодолеть ограниченность данных (слишком распространенный недостаток в мире речи) с помощью трюка, позволяющего извлекать лингвистические особенности путем предварительной тренировки с большим корпусом данных, чтобы он научился восстанавливать вводимый голос. Эти функции служат полезной отправной точкой для обучения переносу в ограниченном объеме данных. Предложенная архитектура несколько усложнена, поскольку в ней используется иерархическое сокращение количества временных шагов на стороне кодировщика. Основой для этого предложения послужил тот факт, что содержимое, встроенное во входные сигналы, рассматриваемое как слова или фонемоподобные объекты, намного меньше, чем размер самих сигналов (5 слов против 100 аудиокадров, 10 фонем против 100 аудиокадров и т.д.). Благодаря этой интуиции, иерархическое сокращение временных интервалов рассматривается как механизм извлечения фонемоподобных объектов путем сжатия содержимого входной mel-спектрограммы. В некотором смысле, наша задача состоит в том, чтобы извлечь независимое от стиля представление на стороне кодировщика. Затем декодер обучается вводить контент целевого диктора, используя точно такую же архитектуру, как и в Tacotron works. Выходные спектрограммы преобразуются обратно в аудио с помощью вокодера WaveNet, что дает правдоподобные преобразования, демонстрирующие, что наш подход действительно оправдан.
Система чувствительна к гиперпараметрам. Мы заметили, что пропускная способность сети CBH особенно важна, и добавление отсева в разных местах помогает обобщить небольшой набор данных. Однако отсев также приводит к "размытости’. Очистка выходных данных, вероятно, необходима с помощью postnet, которую мы не реализовали.
Мы надеемся выпустить код и образцы, которые позволят поэкспериментировать.