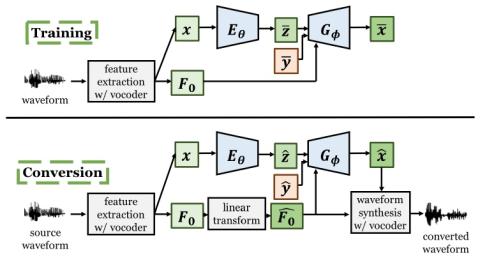
В этой работе мы исследуем эффективность двух методов улучшения преобразования голоса на основе вариационного автоэнкодера (VAE). Во-первых, мы пересматриваем взаимосвязь между характеристиками вокодера, получаемыми с помощью высококачественных вокодеров, используемых в обычных системах преобразования голоса, и выдвигаем гипотезу о том, что спектральные характеристики на самом деле зависят от F0. Такая гипотеза подразумевает, что на этапе преобразования скрытые коды и преобразованные функции при преобразовании голоса на основе VAE фактически зависят от источника F0. С этой целью мы предлагаем использовать F0 в качестве дополнительного входного сигнала декодера. Модель может научиться отличать скрытый код от F0 и, таким образом, генерировать преобразованные функции, зависящие от F0. Во-вторых, чтобы лучше уловить временные зависимости спектральных характеристик и паттерна F0, мы заменили структуру преобразования по кадрам в оригинальной системе преобразования голоса на основе VAE на полностью сверточную сетевую структуру. Наши эксперименты показывают, что степень разборчивости, а также естественность преобразованной речи действительно улучшаются.
Обсуждения и выводы
В этой работе мы исследовали два подхода к улучшению VA-VC. Была применена структура FCN, позволяющая принимать последовательные входные данные, а не выполнять преобразование кадр за кадром, что позволяет фиксировать временную взаимосвязь речи. Механизм настройки F0, основанный на пересмотре взаимосвязи между функциями вокодера, помогает устранить остаточную информацию о F0 в скрытом коде, которая потенциально может повлиять на эффективность преобразования. Экспериментальные оценки показали, что влияние концентрации на объективные показатели и субъективную оценку естественности речи было положительным. С другой стороны, обработка F0 показала многообещающие результаты в повышении степени распознавания скрытых кодов и позволила достичь высокого качества речи, эквивалентного FCN-CDVAE.
Мы объясняем незначительное улучшение, достигнутое с помощью схемы кондиционирования F0, несоответствием между тренировкой и преобразованием. Преобразованный F0, полученный с помощью такого простого процесса преобразования F0, принятого в этой и многих предыдущих работах, далек от естественного. В результате на этапе преобразования входная комбинация, которая состояла из скрытых кодов, извлеченных из обычных MCC, и неестественного преобразованного F0, могла не быть замечена моделью во время обучения, что приводило к ухудшению качества.
Хотя вышеупомянутое несоответствие может быть одной из возможных причин, мы хотели бы подчеркнуть, что, хотя мотивация применения F0-кондиционирования к VAE-VC была основана на предположении, что спектральные характеристики вокодера зависят от F0, конструкция вокодеров заключалась в том, чтобы максимально разделить эти две характеристики. Объем информации о F0, содержащейся в спектральных характеристиках, может быть уже достаточно мал, чтобы наш предложенный механизм мог исключить его. В будущем мы планируем применить эту общую идею к более простым входным характеристикам, которые содержат больше F0, например, к спектрограммам магнитуд.