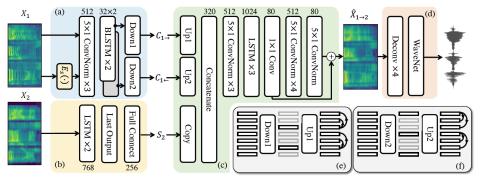
Непараллельное преобразование голоса "многие ко многим", а также преобразование голоса с нулевым кадром остаются недостаточно изученными областями. Алгоритмы глубокой передачи стилей, такие как генеративные состязательные сети (GAN) и условно-вариационный автоэнкодер (CVAE), применяются в качестве новых решений в этой области. Однако обучение стрельбе из пистолета является сложным процессом, и нет убедительных доказательств того, что генерируемая им речь обладает хорошим качеством восприятия. С другой стороны, обучение CVAE является простым, но не обладает свойством сопоставления с распределением, присущим GAN. В этой статье мы предлагаем новую схему передачи стиля, которая использует только автоэнкодер с тщательно разработанным узким местом. Мы формально показываем, что эта схема может обеспечить передачу стиля, соответствующего распределению, путем обучения только при потере самореализации. Основываясь на этой схеме, мы предложили AUTOVC, который обеспечивает самые современные результаты при преобразовании голоса "многие ко многим" с непараллельными данными и который является первым, кто выполняет преобразование голоса с нулевой частотой.
Вывод
В этой статье мы предложили AUTOVAC, непараллельный алгоритм преобразования голоса, который значительно превосходит существующие современные решения и который является первым, который выполняет преобразования с нулевым ускорением. Резким контрастом с его производительностью является простая структура автоэнкодера, которая работает только на самовосстановлении, и настройка узкого места, позволяющая сбалансировать качество восстановления и разборчивость говорящих. В эпоху создания все более сложных алгоритмов передачи стилей наше теоретическое обоснование и успех AUTOVC свидетельствуют о том, что пришло время вернуться к простоте, потому что иногда автоэнкодер с тщательно продуманным дизайном узких мест - это все, что вам нужно, чтобы изменить ситуацию к лучшему.