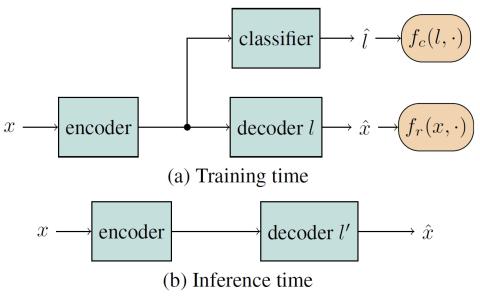
Мы представляем метод преобразования голоса между несколькими говорящими. Наш метод основан на обучении нескольких путей автоэнкодирования, где имеется один кодер, независимый от говорящего, и несколько декодеров, зависящих от говорящего. Автоэнкодеры обучаются с добавлением потерь при столкновении, которые обеспечиваются вспомогательным классификатором, чтобы выходные данные кодера были независимыми от диктора. Обучение модели проходит без контроля в том смысле, что для этого не требуется собирать одинаковые высказывания от говорящих и не требуется время на согласование фонем. Благодаря использованию одного кодировщика, наш метод может быть обобщен для преобразования голоса дикторов, не прошедших обучение, в голоса дикторов из набора обучающих данных. Мы представляем субъективные тесты, подтверждающие эффективность нашего метода.
Обсуждение
Мы представили метод преобразования голоса с использованием нейронных сетей, обученных на непараллельных данных. Метод основан на обучении нескольких путей автоэнкодирования, где имеется один кодер, независимый от диктора, и несколько декодеров, зависящих от диктора. Пути автоэнкодера обучены таким образом, чтобы свести к минимуму ошибку восстановления и издержки, связанные с тем, что выходные данные кодера не содержат никакой информации об идентификаторе говорящего. Обучение не контролируется в том смысле, что нам не требуется параллельный набор речевых данных от говорящих. Мы проверили наш метод на подгруппе дикторов из набора данных VCTK. С качественной точки зрения мы видим, что преобразованные спектрограммы содержат характеристики спектрограмм целевого диктора. Результаты субъективных тестов подтверждают эффективность преобразования голоса нашим алгоритмом. Хотя наш алгоритм может преобразовать голос диктора-источника в направлении цели, мы видим, что восстановленный звук содержит некоторые искажения. Работа по устранению этих искажений продолжается.