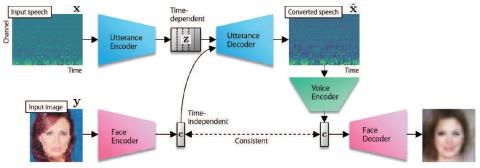
Люди способны представить себе голос человека по его внешности, а внешность человека - по его голосу. В этой статье мы предпринимаем первую попытку разработать метод, который может преобразовывать речь в голос, соответствующий входному изображению лица, и генерировать изображение лица, соответствующее голосу во входной речи, используя корреляцию между лицами и голосами. Мы предлагаем модель, состоящую из преобразователя речи, кодера/декодера лиц и кодера голоса. Мы используем скрытый код входного изображения лица, закодированного лицевым кодером, в качестве вспомогательного входного сигнала для речевого преобразователя и обучаем речевой преобразователь таким образом, чтобы исходный скрытый код мог быть восстановлен из сгенерированной речи голосовым кодером. Мы также обучаем декодер лиц вместе с кодером лиц, чтобы гарантировать, что скрытый код будет содержать достаточно информации для восстановления входного изображения лица. Мы экспериментально подтвердили, что речевой преобразователь, обученный таким образом, способен преобразовывать входную речь в голос, соответствующий входному изображению лица, и что голосовой кодер и декодер лиц могут быть использованы для генерации изображения лица, соответствующего голосу входной речи.
Выводы
В этой статье описана первая попытка решить проблему кросс-модального преобразования голоса путем внедрения расширения ранее предложенного нами метода непараллельного преобразования голоса под названием ACVAE-VC. В ходе экспериментов с использованием виртуального набора данных, объединяющего наборы данных VCC2018 и CelebA, мы подтвердили, что наш метод может преобразовывать вводимую речь в голос, который соответствует вводимому вспомогательному изображению лица, и генерировать изображение лица, которое достаточно хорошо соответствует вводимой речи. Мы также заинтересованы в разработке кросс-модальной системы преобразования текста в речь, где задача состоит в том, чтобы синтезировать речь из текста с голосовыми характеристиками, определяемыми вспомогательным вводом изображения лица.