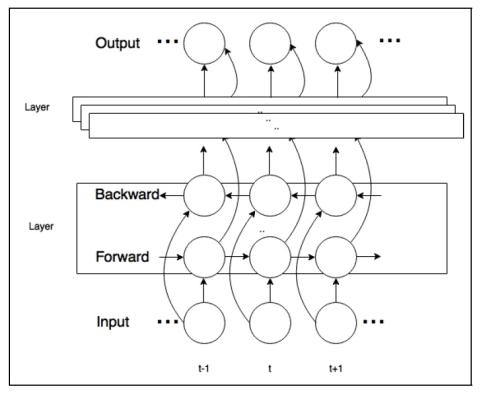
Преобразование певческого голоса - это задача по преобразованию песни, исполняемой певцом-источником, в голос певца-получателя. В этой статье мы предлагаем использовать метод параллельного преобразования множества голосов в один без использования данных для поющих голосов. Фонетическая задняя характеристика сначала генерируется путем декодирования певческих голосов с помощью надежного механизма автоматического распознавания речи (ASR). Затем обученная рекуррентная нейронная сеть (RNN) со структурой глубокой двунаправленной долговременной кратковременной памяти (DBLSTM) используется для моделирования отображения контента, не зависящего от личности, на акустические характеристики целевого пользователя. Значения F0 и aperiodic получены с использованием исходного певческого голоса и используются с акустическими характеристиками для восстановления целевого певческого голоса с помощью вокодера. В полученном певческом голосе целевой и исходный вокалисты звучат одинаково. Насколько нам известно, это первое исследование, в котором используются непараллельные данные для обучения системы преобразования певческого голоса. Субъективные оценки показывают, что предложенный метод эффективно преобразует певческие голоса.
Вывод
Мы предлагаем новую систему, позволяющую использовать параллельное преобразование многих голосов в один без передачи данных при преобразовании голоса певца. ASR, не зависящий от говорящего, сначала используется для извлечения фонетической последовательности задних строк для представления контента, не зависящего от человека, а модель DBLSTM используется для моделирования сопоставления контента, не зависящего от человека, с акустическими характеристиками целевого говорящего. Эти акустические характеристики используются для синтеза целевого певческого голоса с помощью вокодера вместе с F0 и непериодической информацией, извлеченной из исходного контента.
Насколько нам известно, это первая попытка использовать непараллельные данные для обучения модели преобразования певческого голоса. Кроме того, субъективная оценка показывает, что предложенный метод эффективен без использования параллельных данных.
В будущем авторы хотели бы собрать больше данных о певческом голосе для адаптации модели распознавания речи для дальнейшего повышения производительности. В нашей будущей работе мы также надеемся изучить нейронные вокодеры, такие как wavenet, недавно предложенный метод, который демонстрирует превосходную производительность по сравнению с традиционными вокодерами.