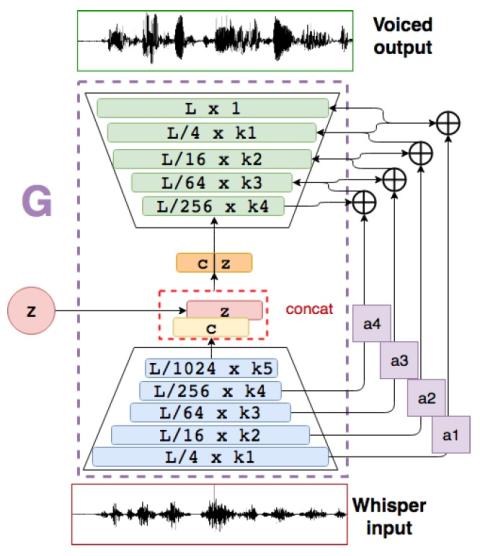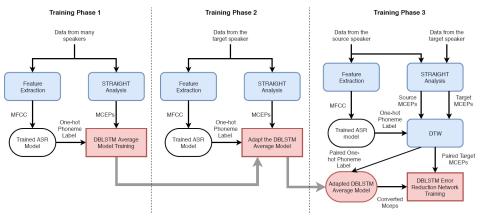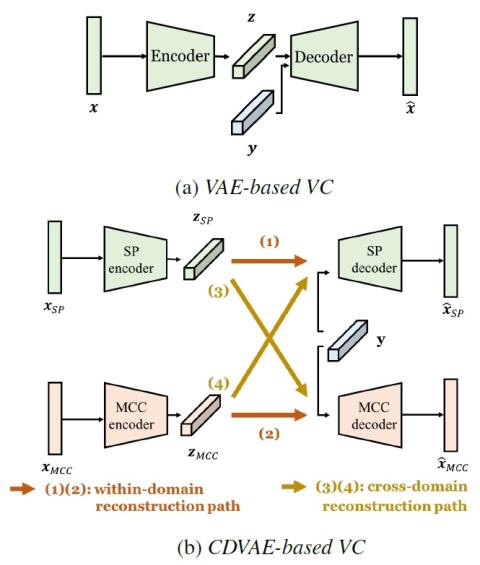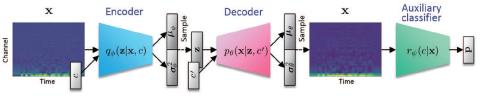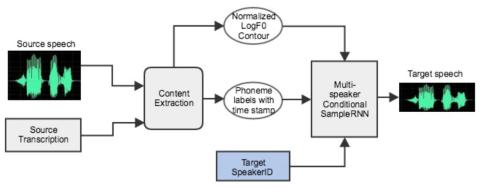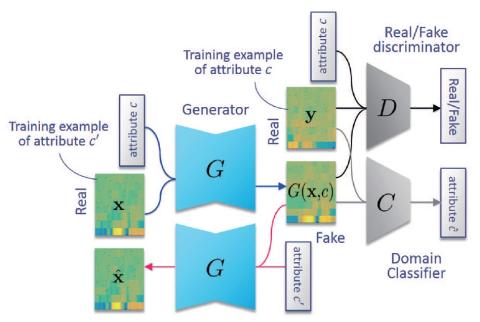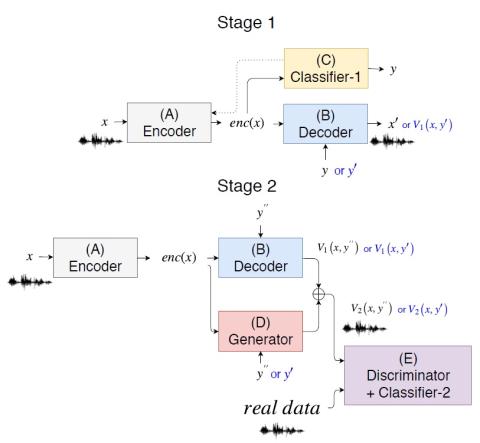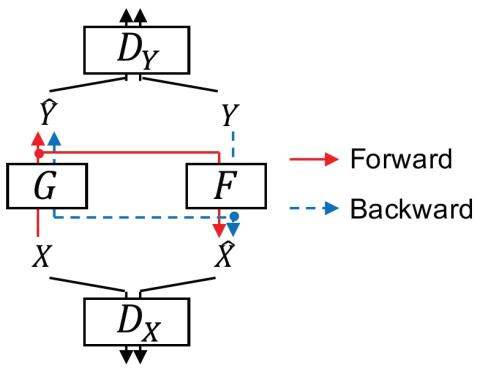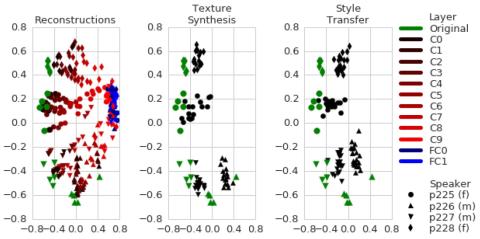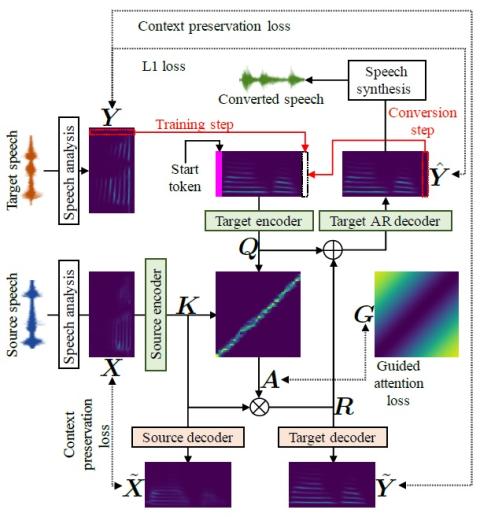
AttS2S-VC: Преобразование голоса от последовательности к последовательности с механизмами сохранения внимания и контекста
В этой статье описывается метод, основанный на последовательном обучении (Seq2Seq) с механизмом сохранения внимания и контекста для задач преобразования голоса. Seq2Seq отлично справляется с многочисленными задачами, связанными с моделированием последовательности, такими как синтез и распознавание речи, машинный перевод и создание субтитров к изображениям. В отличие от современных методов преобразования голоса, наш метод 1) стабилизирует и ускоряет процедуру обучения за счет учета направленного внимания и предполагаемых потерь при сохранении контекста, 2) позволяет преобразовывать не только сп...