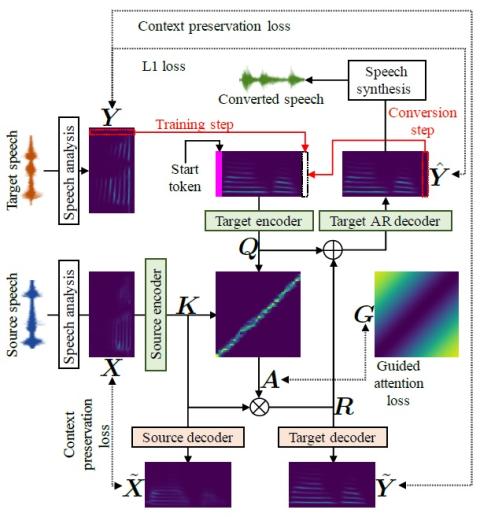
В этой статье описывается метод, основанный на последовательном обучении (Seq2Seq) с механизмом сохранения внимания и контекста для задач преобразования голоса. Seq2Seq отлично справляется с многочисленными задачами, связанными с моделированием последовательности, такими как синтез и распознавание речи, машинный перевод и создание субтитров к изображениям. В отличие от современных методов преобразования голоса, наш метод 1) стабилизирует и ускоряет процедуру обучения за счет учета направленного внимания и предполагаемых потерь при сохранении контекста, 2) позволяет преобразовывать не только спектральные огибающие, но и основные частотные контуры и длительность речи, 3) не требует контекстной информации, такой как фонематические метки, и 4) не требуется заблаговременная синхронизация исходных и целевых речевых данных. В нашем эксперименте предложенный фреймворк преобразования голоса можно обучить всего за один день, используя только один графический процессор NVIDIA Tesla K80, при этом качество синтезированной речи выше, чем у речи, преобразованной с помощью преобразования голоса на основе модели гауссовой смеси, и сравнимо с качеством речи, сгенерированной рекуррентными нейронными сетями. Сетевой синтез текста в речь можно рассматривать как верхний предел производительности преобразования голоса.
Выводы
Мы предложили метод, основанный на обучении Seq2Seq с использованием механизмов сохранения внимания и контекста для задач преобразования голоса. Результаты экспериментов показали, что предложенный метод превосходит традиционное преобразование голоса на основе GMM и сопоставим с TTS на основе LSTM. Продолжается работа над расширением предлагаемого метода, с тем чтобы его можно было использовать в учебных заданиях с частичным контролем. Обратите внимание, что, поскольку мы также одновременно разработали сверточную версию предлагаемого метода, мы проведем дальнейшие оценки и сообщим о результатах.