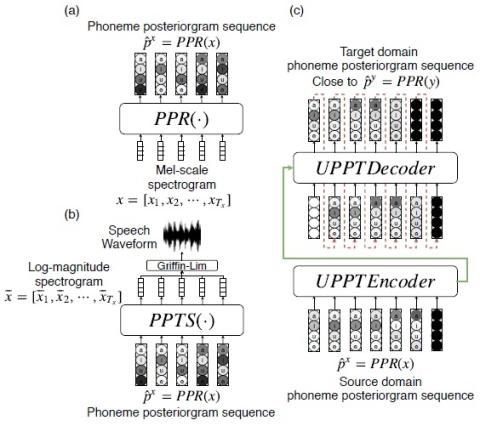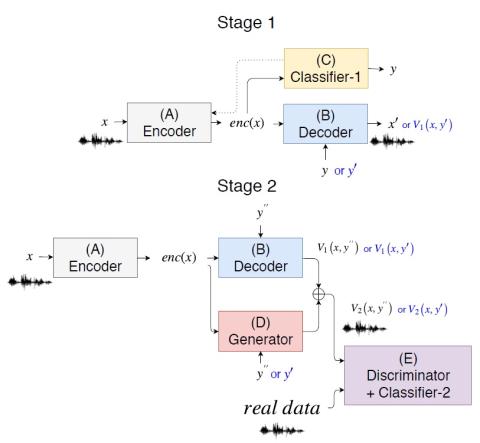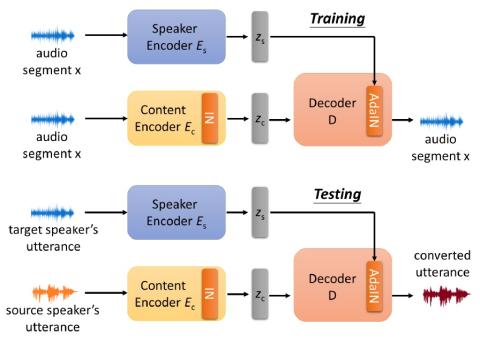
Однократное преобразование голоса путем разделения представлений диктора и контента с нормализацией экземпляра
Недавно преобразование голоса без параллельных данных было успешно адаптировано к многоцелевому сценарию, в котором одна модель обучается преобразованию вводимого голоса для множества различных говорящих. Однако такая модель страдает тем ограничением, что она может преобразовывать голос только дикторов в обучающих данных, что сужает применимый сценарий преобразования голоса. В этой статье мы предложили новый подход к однократному преобразованию голоса, который позволяет выполнять преобразование голоса только с помощью примера произнесения от исходного и целевого диктора соответственно, при это...