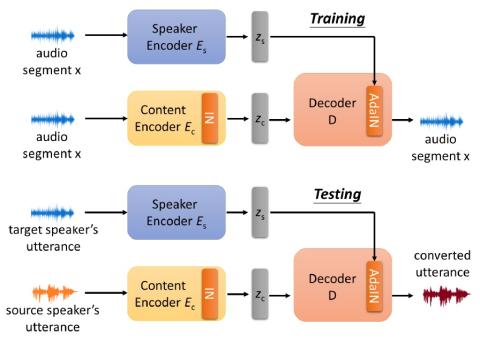
Недавно преобразование голоса без параллельных данных было успешно адаптировано к многоцелевому сценарию, в котором одна модель обучается преобразованию вводимого голоса для множества различных говорящих. Однако такая модель страдает тем ограничением, что она может преобразовывать голос только дикторов в обучающих данных, что сужает применимый сценарий преобразования голоса. В этой статье мы предложили новый подход к однократному преобразованию голоса, который позволяет выполнять преобразование голоса только с помощью примера произнесения от исходного и целевого диктора соответственно, при этом источник и целевой диктор даже не должны быть видны во время обучения. Это достигается путем разделения представлений диктора и контента с помощью нормализации экземпляра (IN). Объективная и субъективная оценка показывает, что наша модель способна генерировать голос, похожий на голос целевого диктора. В дополнение к измерению производительности, мы также демонстрируем, что эта модель способна запоминать осмысленные высказывания диктора без какого-либо контроля.
Вывод
Мы предложили новый подход к однократному неконтролируемому преобразованию голоса, применив нормализацию экземпляра, чтобы заставить модель изучать факторизованные представления. Таким образом, мы можем выполнять преобразование голоса для невидимых дикторов всего одним произнесением. Субъективная и объективная оценки показали хороший результат с точки зрения сходства с целевыми дикторами. Кроме того, эксперименты по распутыванию и визуализации показали, что в предлагаемом нами подходе кодировщик говорящих запоминает значимое пространство для встраивания без какого-либо контроля.