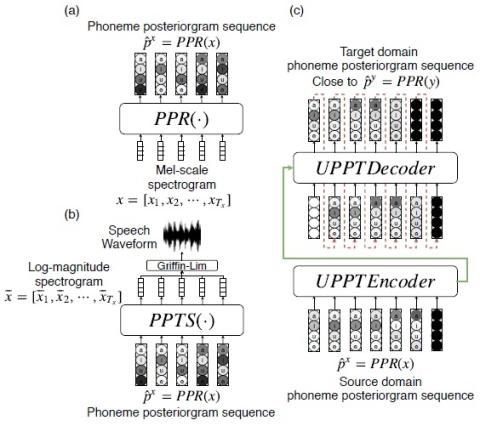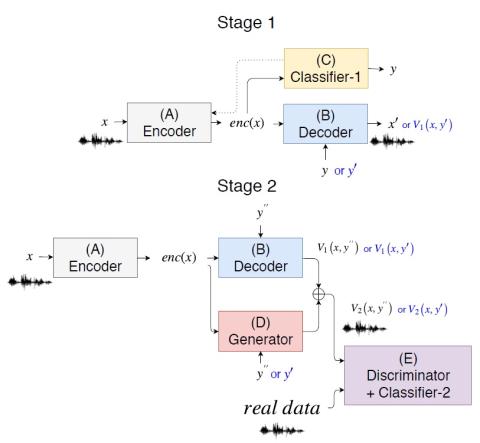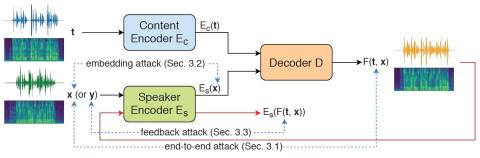
Защита вашего голоса: состязательная атака на преобразование голоса
В последние годы были достигнуты существенные улучшения в преобразовании голоса, которое преобразует характеристики диктора в характеристики другого диктора без изменения лингвистического содержания высказывания. Тем не менее, усовершенствованные технологии преобразования также привели к проблемам конфиденциальности и аутентификации. Таким образом, становится очень желательным иметь возможность предотвратить неправильное использование своего голоса с помощью таких технологий преобразования голоса. Вот почему мы сообщаем в этой статье о первой известной попытке выполнить состязательную атаку на...