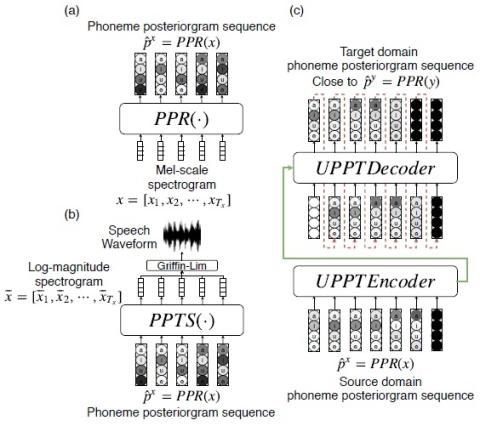
Скорость произнесения относится к среднему количеству фонем за единицу времени, в то время как ритмические паттерны относятся к распределению длительности для реализации разных фонем в разных фонетических структурах. И то, и другое является ключевыми компонентами просодии в речи, которая отличается у разных носителей языка. Такие модели, как cycle-consistent adversarial network (Cycle-GAN) и variational auto-encoder (VAE), успешно применяются для решения задач преобразования голоса без параллельных данных. Однако из-за архитектуры нейронных сетей и векторов характеристик, выбранных для этих подходов, длина прогнозируемого высказывания должна быть привязана к длине входного высказывания, что ограничивает гибкость в имитации темпа речи и ритмических паттернов для целевого говорящего. С другой стороны, для устранения вышеуказанного ограничения по длине была использована модель последовательного обучения, но необходимы данные параллельного обучения. В этой статье мы предлагаем подход, использующий модель "последовательность за последовательностью", обученную с помощью неконтролируемого Cycle-GAN, для выполнения преобразования между последовательностями фонемных постерограмм для разных носителей языка. Таким образом, ограничение длины, упомянутое выше, устранено, что позволяет осуществлять преобразование голоса с гибкостью ритма, не требуя параллельных данных. Предварительная оценка двух наборов данных показала очень обнадеживающие результаты.
Вывод
Объективная и субъективная оценка на двух разных наборах данных показала, что предложенный подход способен имитировать голосовые характеристики целевого носителя, включая скорость речи и ритмические паттерны, без параллельных данных, используя последовательное обучение с помощью Cycle-GAN для устранения ограничения по длине. Хотя границы фонем необходимы для получения обучающих данных, легко доступный предварительно обученный программист может предложить эти границы.