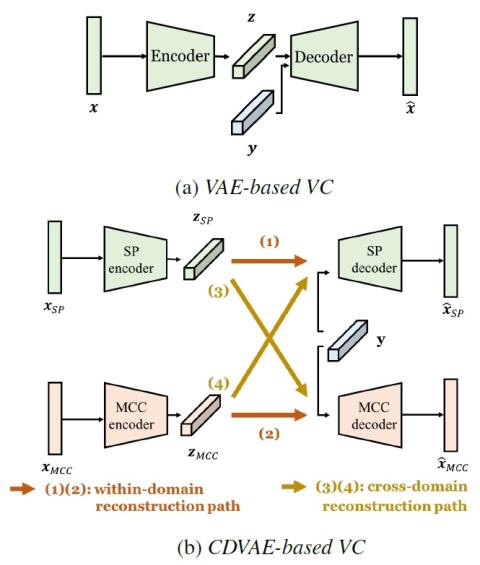
Эффективным подходом к непараллельному преобразованию голоса является использование глубоких нейронных сетей (DNN), в частности вариационных автокодеров (VAE), для моделирования скрытой структуры речи неконтролируемым образом. Предыдущее исследование подтвердило эффективность VAE, использующего ПРЯМЫЕ спектры для преобразования голоса. Однако, VAE, использующие другие типы спектральных характеристик, такие как мелкоцепстральные коэффициенты (MCC), которые связаны с восприятием человека и широко используются при преобразовании голоса, не были должным образом исследованы. Ожидается, что вместо использования одного конкретного типа спектральных характеристик VAE может извлечь выгоду из одновременного использования нескольких типов спектральных характеристик, тем самым улучшая возможности VAE по преобразованию голоса. С этой целью мы предлагаем новую платформу VAE (называемую междоменной VAE, CDVAE) для преобразования голоса. В частности, предлагаемая структура использует как прямые спектры, так и MCC, явно упорядочивая множество задач, чтобы ограничить поведение обученного кодера и декодера. Экспериментальные результаты показывают, что предложенная система CDVAE превосходит традиционную систему VAE с точки зрения субъективных тестов.
Обсуждение
В разделе 4 мы показали, что предлагаемая нами платформа CDVAE успешно использует междоменные функции для улучшения возможностей VAE по преобразованию голоса и превосходит базовую систему преобразования голоса на основе VAE в субъективных тестах. Вопрос в том, какую пользу наша структура приносит лежащей в ее основе речевой модели?
Напомним, что жизнеспособность фреймворка VAE зависит от декомпозиции входных фреймов, которые, как предполагается, состоят из скрытого кода (при преобразовании голоса, фонетического кода или лингвистического содержимого) и кода говорящего. В идеале, при применении VAE для преобразования голоса скрытый код должен содержать исключительно фонетическую информацию о кадре, без какой-либо информации о говорящем. Однако такая декомпозиция явно не гарантируется. Созданные вручную объекты, такие как SP или MCC, обладают своей собственной природой, поэтому даже для одного и того же входного кадра информация, необходимая для восстановления входных данных из разных областей объектов, может отличаться. При обучении только с одной функцией в скрытом коде остается только необходимая информация для восстановления этой функции, таким образом, фреймворк VAE может слишком хорошо соответствовать свойству этой конкретной функции, теряя способность к обобщению. Один из способов усилить декомпозицию - привлечь к обучению как можно больше дикторов, что не обязательно приведет к улучшению декомпозиции. Предложенный нами фреймворк заставляет кодировщик действовать скорее как распознаватель телефонных разговоров, не зависящий от говорящего, и таким образом отфильтровывает ненужную, зависящую от говорящего информацию о вводимом элементе. В результате наш фреймворк не только обеспечивает соответствие свойств междоменных объектов, но и позволяет лучше распознавать скрытое представление речи.
В будущем мы планируем более подробно исследовать вышеприведенное предположение. Кроме того, генеративная состязательная сеть Вассерштейна (WGAN) [24] была внедрена в традиционный метод преобразования голоса на основе VAE [18] для улучшения естественности преобразованного голоса, поэтому мы также планируем внедрить WGAN в предлагаемую структуру.