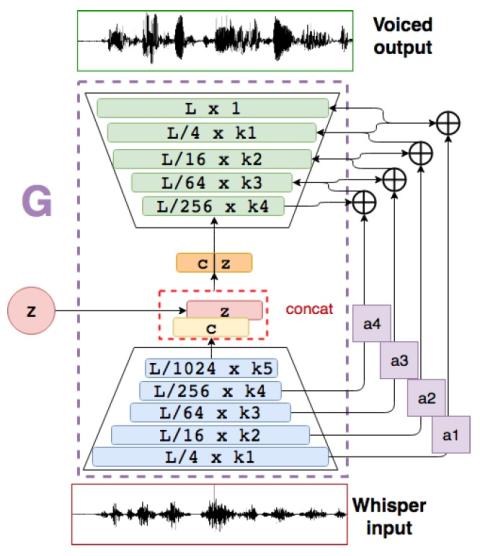
Большинство методов восстановления голоса у пациентов, страдающих афонией, позволяют говорить шепотом или монотонно. Помимо разборчивости, этому типу речи не хватает выразительности и естественности из-за отсутствия тембра (речь шепотом) или его искусственного создания (монотонная речь). Существующие методы восстановления просодической информации обычно сочетают вокодер, который параметризует речевой сигнал, с методами машинного обучения, которые предсказывают просодическую информацию. В отличие от этого, в этой статье описывается комплексный нейронный подход к оценке формы сигнала полностью озвученной речи на основе аларингеального шепота. Адаптируя нашу предыдущую работу по улучшению речи к генеративным состязательным сетям, мы разработали модель, зависящую от говорящего, для преобразования шепотного голоса в гортанный. Предварительные качественные результаты показывают эффективность в восстановлении голосовой речи с созданием реалистичных контуров высоты тона.
Выводы
Мы представили сквозную генерирующую состязательную сеть, зависящую от говорящего, которая будет выполнять функцию постфильтра шепотной речи для устранения патологических изменений в приложении. Мы адаптировали нашу предыдущую архитектуру усиления речи, чтобы преодолеть проблемы с несоосностью, и при этом получили стабильную архитектуру GAN для восстановления голосовой речи. Модель способна генерировать новые звуковысотные контуры, видя на входе только произнесенную шепотом версию речи. Этот метод генерирует более насыщенные кривые, чем базовый вариант, который звучит монотонно с точки зрения просодии. Будущие направления работы включают в себя еще более комплексный подход, основанный на преобразовании сенсоров в речь. Кроме того, необходимы дальнейшие исследования для устранения характерных высокочастотных искажений, вызванных типом архитектуры децимации-интерполяции, на которой мы основываем наш дизайн.