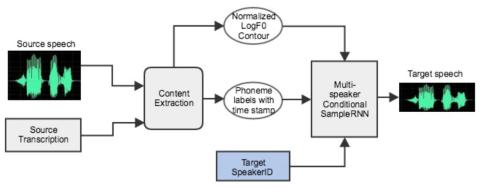
Здесь мы представляем новый подход к созданию генерирующей модели SampleRNN для преобразования голоса. Традиционные методы преобразования голоса изменяют воспринимаемую идентичность говорящего путем преобразования между исходными и целевыми акустическими характеристиками. Наш подход направлен на сохранение голосового контента и зависит от генерирующей сети для преобразования голоса. Сначала мы обучаем модель выборки для нескольких говорящих, основанную на лингвистических особенностях, контуре высоты тона и идентичности говорящего, используя корпус речи для нескольких говорящих. Преобразованная в голос речь генерируется с использованием лингвистических характеристик и контура высоты тона, выделенных из исходного диктора, а также идентификации целевого диктора. Мы демонстрируем, что наша система способна преобразовывать голос "многие ко многим" без необходимости параллельного обмена данными, что обеспечивает широкое применение. Субъективная оценка показывает, что наш подход превосходит традиционные методы преобразования голоса.
Выводы
В этой статье мы предложили метод преобразования голоса в зависимости от текста, основанный на модели генерации речи на основе SampleRNN. Преимущество предлагаемого метода заключается в том, что он не требует параллельного набора данных и не имеет ограничений для носителей исходного текста. Результаты экспериментов демонстрируют, что предложенный метод значительно улучшает естественность речи по сравнению с базовой системой при гораздо более высокой точности преобразования голоса. В будущей работе мы планируем еще больше улучшить качество речи и разработать сквозной метод преобразования голоса, не зависящий от текста.