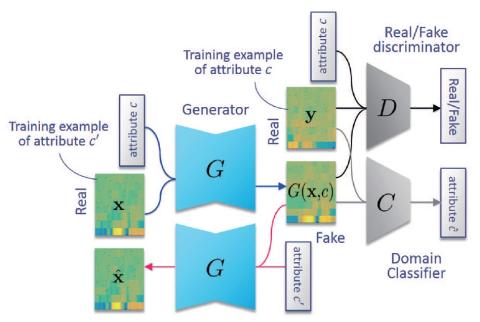
В этой статье предлагается метод, который позволяет осуществлять непараллельное преобразование голоса "многие ко многим" с использованием варианта генеративной состязательной сети (GAN) под названием StarGAN. Наш метод, который мы называем StarGAN-VC, примечателен тем, что он (1) не требует параллельного произнесения, транскрипции или процедур выравнивания по времени для обучения генератора речи, (2) одновременно изучает сопоставления "многие ко многим" в разных областях атрибутов, используя единую сеть генераторов, (3) способен генерировать преобразованные речевые сигналы достаточно быстро, чтобы обеспечить реализацию в режиме реального времени, и (4) требуется всего несколько минут обучающих примеров для генерации достаточно реалистично звучащей речи. Эксперименты по субъективной оценке в непараллельной задаче преобразования голоса "многие ко многим" показали, что предложенный метод обеспечивает более высокое качество звука и сходство дикторов, чем современный метод, основанный на вариационном автоэнкодировании GAN.
Вывод
В этой статье предложен метод, который позволяет осуществлять непараллельное преобразование голоса "многие ко многим" с использованием нового варианта GAN под названием StarGAN. Наш метод, который мы называем StarGAN-VC, примечателен тем, что он (1) не требует параллельного произнесения, транскрипции или процедур выравнивания по времени для обучения генератора речи, (2) одновременно изучает сопоставления "многие ко многим" в разных областях голосовых атрибутов, используя единую сеть генераторов, (3) является способен генерировать сигналы преобразованного голоса достаточно быстро, чтобы обеспечить реализацию в реальном времени, и (4) требует всего нескольких минут обучающих примеров для генерации достаточно реалистично звучащей речи. Эксперименты по субъективной оценке в непараллельной задаче преобразования голоса "многие ко многим" показали, что предложенный метод обеспечивает более высокое качество звука и сходство дикторов, чем базовый метод, основанный на подходе VAE-GAN.