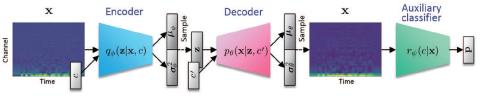
В данной статье предлагается непараллельный метод преобразования голоса "многие ко многим" с использованием варианта условного вариационного автоэнкодера (VAE), называемого вспомогательным классификатором VAE (ACVAE). Предлагаемый метод имеет три ключевые особенности. Во-первых, он использует полностью сверточную архитектуру для построения сетей кодирования и декодирования, чтобы сети могли изучать правила преобразования, которые фиксируют временные зависимости в последовательностях акустических характеристик исходной и целевой речи. Во-вторых, он использует теоретико-информационную регуляризацию для обучения модели, чтобы гарантировать, что информация в метке класса атрибута не будет потеряна в процессе преобразования. При использовании обычных CVAEs кодер и декодер могут игнорировать ввод метки класса атрибута. Это может быть проблематично, поскольку в такой ситуации метка класса атрибута будет оказывать незначительное влияние на управление речевыми характеристиками вводимой речи во время тестирования. Таких ситуаций можно избежать, введя вспомогательный классификатор и обучив кодер и декодер таким образом, чтобы классы атрибутов выходных данных декодера были правильно предсказаны классификатором. В-третьих, это позволяет избежать создания шумной речи во время тестирования, просто перенося спектральные характеристики входной речи в ее преобразованную версию. Эксперименты по субъективной оценке показали, что этот простой метод достаточно хорошо работает в непараллельной задаче преобразования идентификационных данных многих говорящих.
Выводы
В этой статье предлагается непараллельный метод преобразования голоса "многие ко многим" с использованием варианта VAE, называемого вспомогательным классификатором VAE (ACVAE). Предлагаемый метод имеет три ключевые особенности. Во-первых, мы внедрили полностью сверточную архитектуру для построения сетей кодирования и декодирования, чтобы сети могли изучать правила преобразования, которые фиксируют временные зависимости в последовательностях акустических характеристик исходной и целевой речи. Во-вторых, мы предложили использовать теоретико-информационную регуляризацию для обучения модели, чтобы гарантировать, что информация, содержащаяся в скрытой метке атрибута, не будет потеряна в процессе генерации. При использовании обычных CVAEs кодер и декодер могут игнорировать ввод метки класса атрибута. Это может быть проблематично, поскольку в такой ситуации ввод метки класса атрибута будет иметь незначительное влияние на управление речевыми характеристиками вводимой речи. Чтобы избежать подобных ситуаций, мы предложили ввести вспомогательный классификатор и обучить кодер и декодер таким образом, чтобы классы атрибутов выходных данных декодера были правильно предсказаны классификатором. В-третьих, чтобы избежать создания шумной речи во время тестирования, мы предложили просто перенести спектральные характеристики входной речи в ее преобразованную версию. Эксперименты по субъективной оценке в непараллельной задаче преобразования голоса "многие ко многим" показали, что предложенный метод обеспечивает более высокое качество звука и сходство говорящих, чем метод, основанный на VAEGAN.