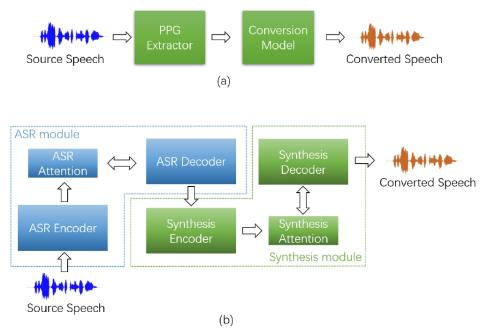
В этой статье предлагается подход к непараллельному преобразованию голоса от любого ко многим относительно местоположения, от последовательности к последовательности (seq2seq), который использует контроль текста во время обучения. В этом подходе мы объединяем экстрактор функций бутылочного горлышка (BNE) с модулем синтеза seq2seq. На этапе обучения обучается гибридный распознаватель фонем коннекционист-временная классификация-внимание (CTC-attention) на основе кодера-декодера, кодер которого имеет слой горлышка бутылки. BNE получается из распознавателя фонем и используется для извлечения независимых от диктора, плотных и богатых представлений разговорного контента из спектральных характеристик. Затем модель синтеза seq2seq, основанная на расположении нескольких дикторов относительно внимания, обучается восстановлению спектральных характеристик по признакам бутылочного горлышка, обусловливая представления дикторов для контроля идентичности дикторов в сгенерированной речи. Чтобы смягчить трудности использования моделей seq2seq для выравнивания длинных последовательностей, мы уменьшаем выборку входного спектрального признака по временному измерению и оснащаем модель синтеза дискретизированной смесью логистического (MoL) механизма внимания. Поскольку распознаватель фонем обучается с большим корпусом данных распознавания речи, предлагаемый подход может проводить преобразование голоса от любого ко многим. Объективные и субъективные оценки показывают, что предлагаемый подход "от любого ко многим" обладает превосходными характеристиками преобразования голоса как с точки зрения естественности, так и сходства дикторов. Исследования абляции проводятся для подтверждения эффективности выбора признаков и стратегий проектирования моделей в предлагаемом подходе. Предлагаемый подход к преобразования голоса может быть легко расширен для поддержки любого преобразования голоса (также известного как преобразования голоса с одним/несколькими проходами) и достижения высокой производительности в соответствии с объективными и субъективными оценками.
Выводы
В этой статье мы разрабатываем предварительный подход для достижения надежного непараллельного подхода seq2seq any-to-many преобразования голоса. Новый подход объединяет распознаватель фонем seq2seq (Seq2seqPR) и сеть информированного внимания с несколькими дикторами (DurIAN) для синтеза. Расширение также сделано на основе этого подхода, чтобы обеспечить поддержку любого преобразования голоса в любой. Тщательные исследования, включая объективные и субъективные оценки, проводятся для этой модели в любых условиях, а также в любых условиях.
Чтобы преодолеть недостатки основанных на PPG и непараллельных подходах seq2seq any-to-many преобразования голоса, мы также предложили новый подход any-to-many преобразования голоса, который сочетает в себе экстрактор функций бутылочного горлышка (BNE) с моделью синтеза seq2seq на основе внимания MoL. Этот подход может быть легко распространен на любое преобразование голоса. Результаты объективной и субъективной оценки показывают его превосходную производительность преобразования голоса как в настройках "от любого ко многим", так и в настройках "от любого к любому". Исследования абляции были проведены для подтверждения эффективности стратегий выбора признаков и проектирования моделей в предлагаемом подходе. Предложенный подход BNE-Seq2seqMoL успешно сократил конвейер преобразования голоса от последовательности к последовательности, чтобы содержать только кодер ASR и декодер синтеза. Однако он по-прежнему использует спектральные характеристики (т. е. спектрограммы mel) в качестве промежуточных представлений и полагается на независимо обученный нейронный вокодер для генерации формы сигнала. Это может снизить качество синтеза, чего можно избежать путем совместного обучения всего конвейера преобразования голоса сквозным способом (т. е. обучение от формы волны к форме волны). В будущем мы также рассмотрим предлагаемый подход с точки зрения передачи исходного стиля и преобразования эмоций.