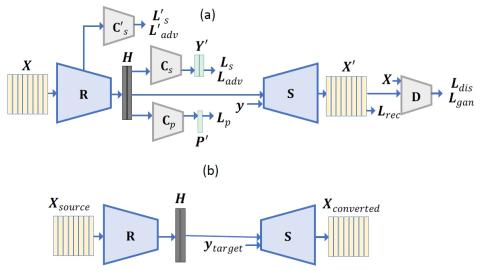
В данной статье представлен метод состязательного обучения для непараллельного преобразования голоса на основе распознавания и синтеза. Распознаватель используется для преобразования акустических признаков в лингвистические представления, в то время как синтезатор восстанавливает выходные признаки из выходных данных распознавателя вместе с идентификатором говорящего. Отделяя характеристики говорящего от лингвистических представлений, преобразование голоса может быть достигнуто путем замены идентификатора говорящего на целевой. В предлагаемом нами методе используется состязательная потеря говорящего, чтобы получить независимые от говорящего лингвистические представления с помощью распознавателя. Кроме того, вводятся дискриминаторы и используются потери в генерирующей состязательной сети (GAN), чтобы предотвратить чрезмерное сглаживание прогнозируемых признаков. Для параметров обучающей модели разработана стратегия предварительного обучения на наборе данных с несколькими дикторами и последующей точной настройки на паре источник-целевой диктор. Наш метод достиг более высокого сходства, чем базовая модель, которая показала наилучшие результаты в Voice Conversion Challenge 2018.
Выводы
В этой статье предлагается метод непараллельного преобразования голоса. Наша модель основана на фреймворке распознавания-синтеза, и для состязательного обучения дикторов введен модуль классификатора говорящих. Мы также учитываем потери GAN для повышения качества преобразованного голоса. Модель сначала предварительно обучается на наборе данных с несколькими дикторами, а затем точно настраивается на желаемую пару преобразований. Как объективные, так и субъективные оценки доказали эффективность нашего метода. В нашей будущей работе мы попытаемся еще больше повысить производительность нашего метода путем предварительного обучения на больших наборах данных.