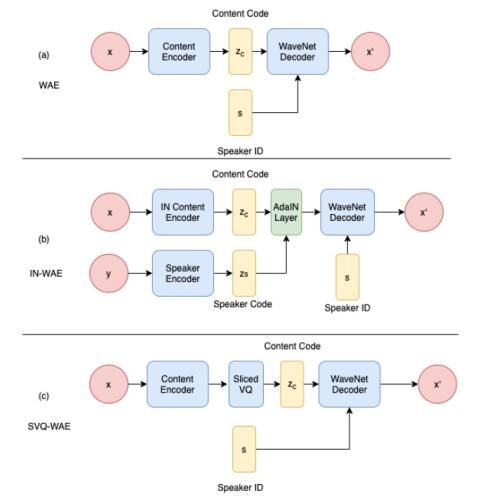
В последние годы изучение речи без присмотра представляет большой интерес, что, например, проявляется в широком интересе к задачам ZeroSpeech. В этой работе представлен новый метод обучения представлений уровня кадров на основе автокодеров WaveNet. Особый интерес в конкурсе "ZeroSpeech Challenge 2019" представляли модели с дискретной скрытой переменной, такие как векторно-квантованный вариационный автокодер (VQVAE). Однако эти модели генерируют речь с относительно низким качеством. В этой работе мы стремимся решить эту проблему с помощью двух подходов: во-первых, WaveNet используется в качестве декодера и для генерации данных формы волны непосредственно из скрытого представления; во-вторых, низкая сложность скрытых представлений улучшается с помощью двух альтернативных методов обучения распутыванию, а именно нормализации экземпляра и квантования срезанных векторов. Метод был разработан и протестирован в контексте недавнего конкурса "ZeroSpeech Сhallenge 2020". Результаты системы, представленные на конкурс, получили верхнюю позицию по естественности (средний балл мнения 4,06), верхнюю позицию по разборчивости (частота ошибок символов 0,15) и третью позицию по качеству представления (оценка теста ABX 12,5). Этот и дальнейший анализ в данной статье иллюстрирует, что качество преобразованной речи и представление акустических единиц могут быть хорошо сбалансированы.
Выводы и будущая работа
Мы предложили включить автокодер WaveNet с нормализацией экземпляра и sliced-VQ соответственно. В конкурсе "ZeroSpeech Challenge 2020" IN-WAE получает конкурентные результаты по естественности, разборчивости и различимости представления. В то же время SVQ-WAE получает различимость конкурентного представления. В будущей работе будут изучены методы, которые могут обеспечить хорошее сходство дикторов для преобразования голоса. Кроме того, будут исследованы методы, которые могут ускорить вывод модели автокодера WaveNet.