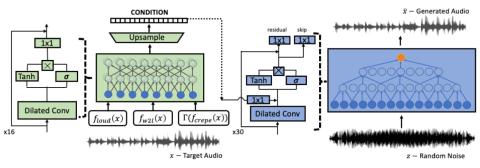
Мы представляем генерирующую модель wav-to-wav для задачи преобразования певческого голоса из любого идентификатора. Наш метод использует как акустическую модель, обученную для задачи автоматического распознавания речи, так и функции извлечения мелодии для управления генератором на основе формы сигнала. Предлагаемая генеративная архитектура инвариантна к личности говорящего и может быть обучена генерировать целевых исполнителей на основе немаркированных обучающих данных, используя либо речевые, либо певческие источники. Модель оптимизируется сквозным образом без какого-либо ручного контроля, такого как тексты песен, музыкальные ноты или параллельные сэмплы. Предлагаемый подход является полностью сверточным и может генерировать аудио в режиме реального времени. Эксперименты показывают, что наш метод значительно превосходит базовые методы, генерируя при этом убедительно лучшие звуковые сэмплы, чем альтернативные попытки.
Вывод
Мы представляем неконтролируемый метод, который может преобразовать поющий голос в голос, который сэмплируется либо как говорящий, либо как поющий. Метод использует множество предварительно обученных кодеров и потери восприятия и позволяет получать самые современные результаты как по объективным, так и по субъективным показателям. Было показано, что настройка генератора на синусоидальное возбуждение является полезной при дальнейшем улучшении результатов. В качестве будущей работы мы хотели бы сосредоточиться на временной модификации входного пения, чтобы оно еще больше соответствовало стилю целевого певца.