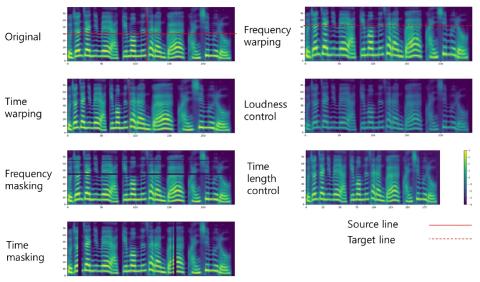
При обучении модели преобразования голоса от последовательности к последовательности нам необходимо решить проблему нехватки данных о количестве речевых кортежей, состоящих из одного и того же высказывания. В этом исследовании было проведено экспериментальное исследование влияния расширения Mel-спектрограммы на модель преобразования голоса от последовательности к последовательности. Для расширения Mel-спектрограммы мы применили правила, предложенные в Spec Augment. Кроме того, мы предлагаем новые правила для большего количества вариаций данных. Чтобы найти оптимальные гиперпараметры политик усиления для преобразования голоса, мы провели эксперименты, основанные на новом показателе, а именно на соотношении деформации к ухудшению. Мы наблюдали их влияние в ходе экспериментов, основанных на различных размерах обучающего набора и комбинациях политик усиления. Согласно результатам эксперимента, политики, основанные на искажении временной оси, показали лучшую производительность, чем другие политики.
Вывод
В этой статье описывается влияние дополнения Mel-спектрограммы на модель преобразования голоса Seq2Seq "один к одному". Мы применили политики из SpecAugment и предложили новые политики для дополнения Mel-спектрограммы. Мы подобрали соответствующие гиперпараметры для каждой политики с помощью экспериментов, основанных на предложенной нами метрике DPD. Результаты экспериментов показали, что зависимость между объемом обучающих данных и лингвистической выразительностью модели преобразования голоса прямо пропорциональна. Кроме того, политики, основанные на искажении временной оси, показали более низкий уровень CAR, чем другие политики. Эти результаты показывают, что использование политик, основанных на искажении временной оси, является более эффективным методом обучения для разработки модели преобразования голоса при недостаточном размере обучающего набора.