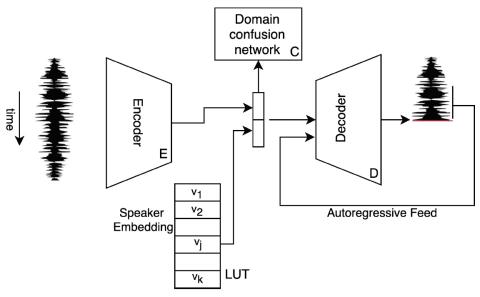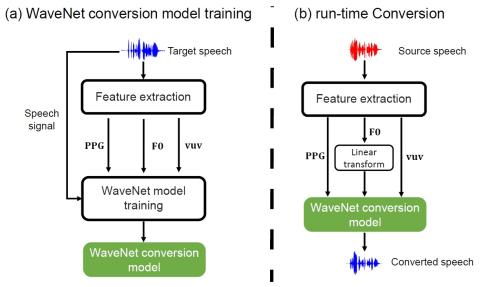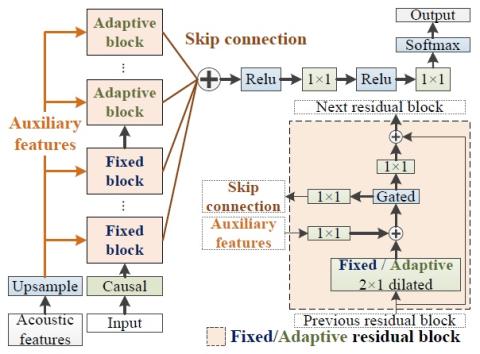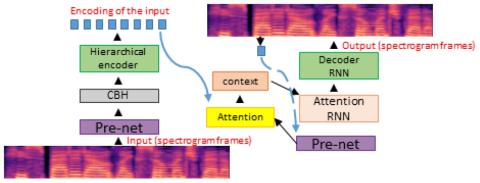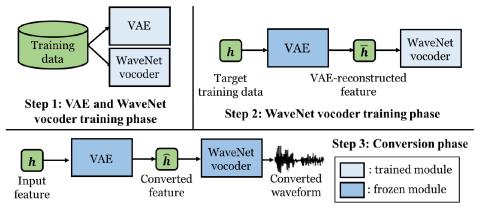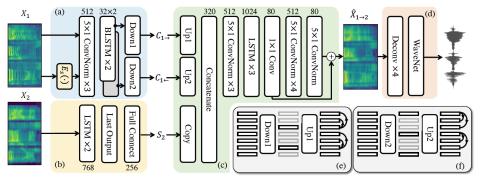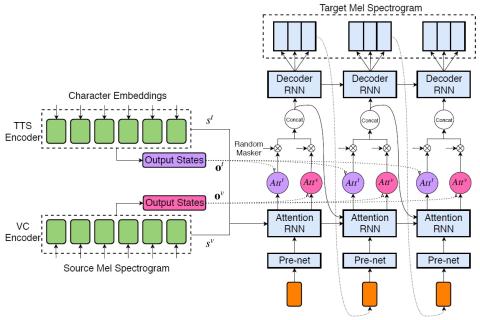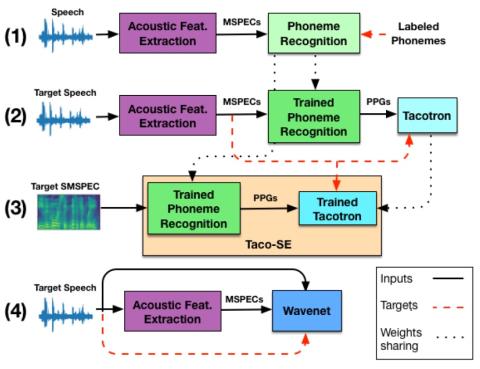
Taco-VC: Преобразование голоса на базе Tacotron с одним говорящим и ограниченным объемом данных
В этой статье представлена Taco-VC, новая архитектура преобразования голоса, основанная на синтезаторе Tacotron, которая представляет собой модель последовательного преобразования голоса с учетом внимания. Обучение систем преобразования голоса с несколькими динамиками требует большого объема ресурсов, как в плане обучения, так и в плане размера корпуса. Taco-VC реализован с использованием синтезатора Tacotron с одним говорящим, основанного на фонетических апостериограммах (PPG), и вокодера Wavenet с одним говорящим, основанного на спектрограммах Mel. Для повышения качества преобразованной речи...