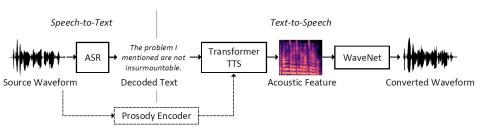
С развитием технологий автоматического распознавания речи (ASR) и синтеза текста в речь (TTS) стало интуитивно понятно построить систему преобразования голоса путем каскадного подключения систем ASR и TTS. В этой статье мы представляем метод ASR-TTS для преобразования голоса, в котором используется механизм iFLYTEK ASR для преобразования исходной речи в текст и модель Transformer TTS с вокодером WaveNet для синтеза преобразованной речи из декодированного текста. Для модели TTS мы предложили использовать код просодии для описания просодической информации, отличной от текста и информации о дикторе, содержащейся в речи. Кодировщик просодии используется для извлечения кода просодии. Во время преобразования исходная просодия преобразуется в преобразованную речь путем согласования модели Transformer TTS с ее кодом. Были проведены эксперименты, чтобы продемонстрировать эффективность предложенного нами метода. Наша система также получила лучшую естественность и сходство в одноязычной задаче Voice Conversion Challenge 2020.
Выводы
В этой статье мы представляем метод преобразования голоса путем каскадного подключения модулей ASR и TTS. Механизм iFLYTEK ASR используется для декодирования текста из исходного высказывания, а модель Transformer TTS обучается для синтеза целевой речи. Transformer TTS предварительно обучается на наборе данных с несколькими дикторами, а затем настраивается на целевом дикторе, чтобы повысить его способность к обобщению. Далее предлагается метод передачи просодии, в котором код просодии извлекается кодировщиком просодии из источника, а затем используется для кондиционирования целевой модели TTS. Наши экспериментальные результаты показали эффективность предложенного метода преобразования голоса. Однако модель ASR все еще несовершенна. Ошибки распознавания речи приведут к изменению лингвистического содержания преобразованной речи. В нашей будущей работе будет изучено, как минимизировать эти ошибки, используя сочетание распознанного текста и функций, связанных с контентом.