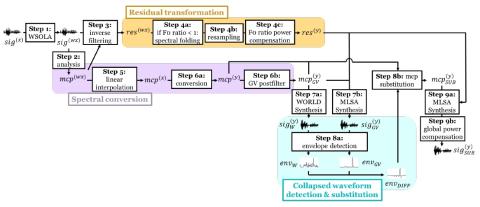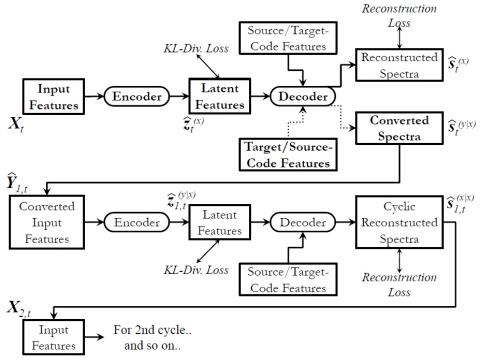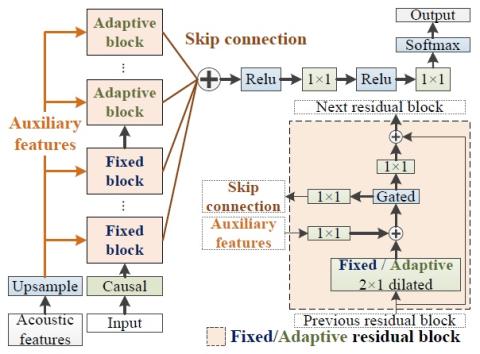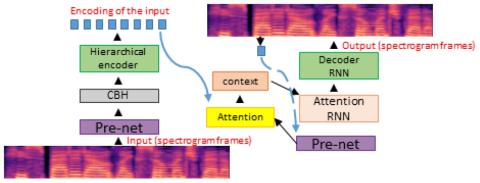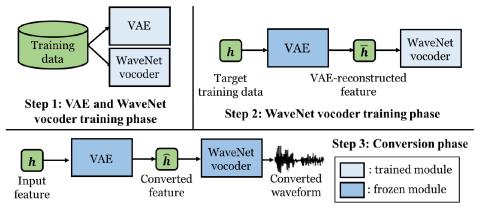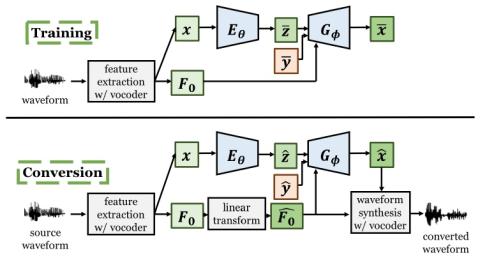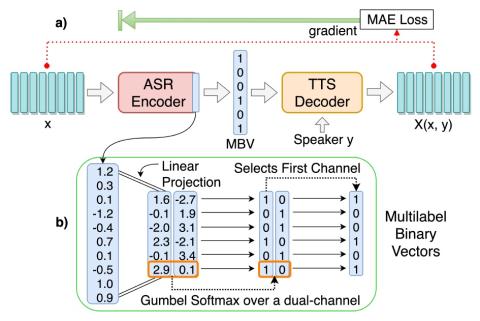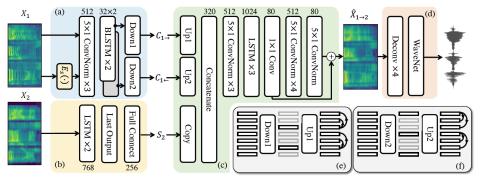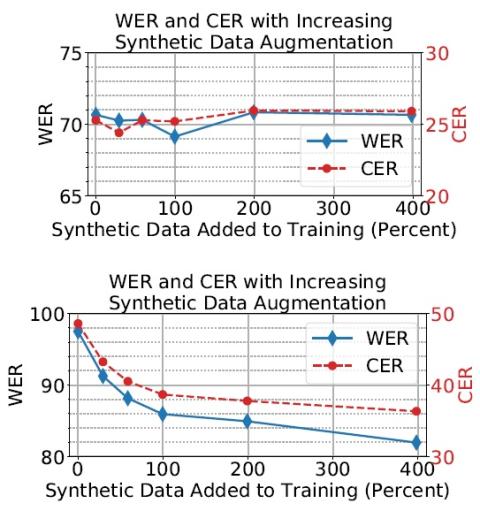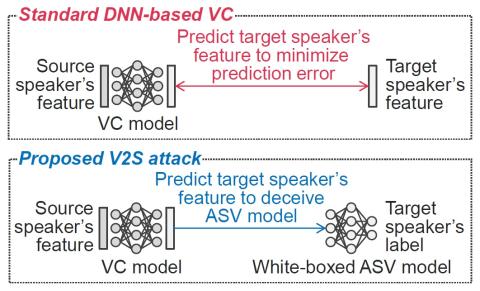
V2S attack: построение преобразования голоса на основе DNN автоматической проверки говорящего
В этой статье представлена новая атака на имитацию голоса с использованием преобразования голоса. Регистрация личных голосов для автоматической проверки говорящего (ASV) предлагает естественные и гибкие системы биометрической аутентификации. В основном, системы ASV не включают голосовые данные пользователей. Однако, если система ASV неожиданно обнаруживается и взламывается злоумышленником, существует риск того, что злоумышленник будет использовать методы преобразования голоса для воспроизведения голосов зарегистрированных пользователей. Мы называем это атакой от проверки к синтезу (V2S)" и пре...