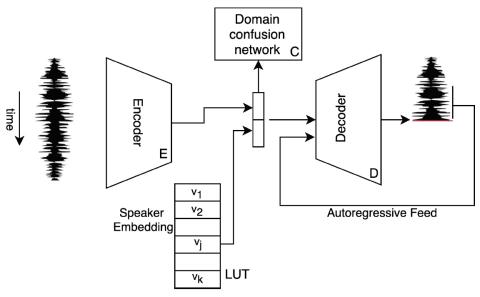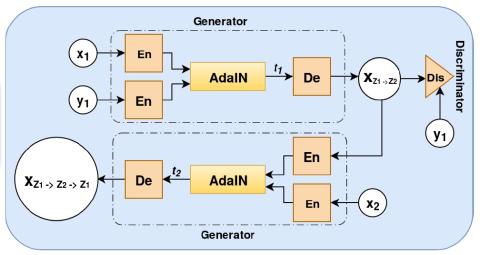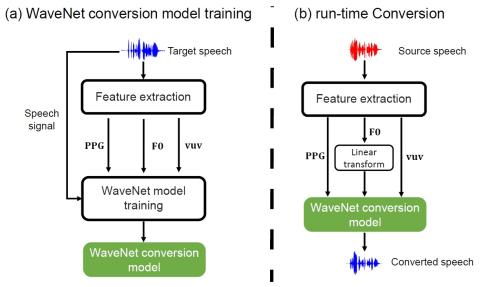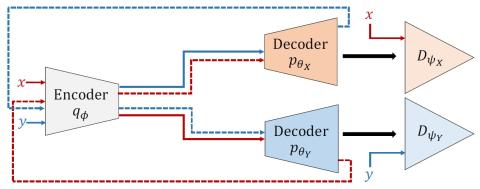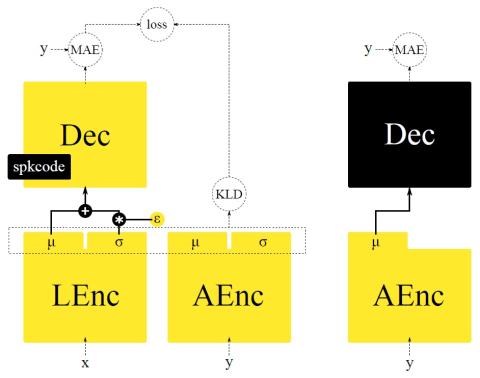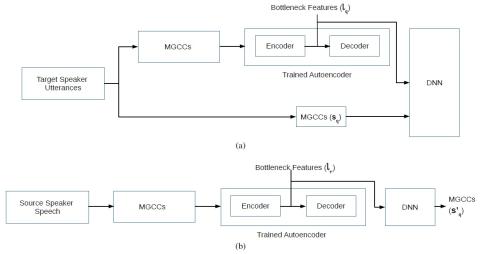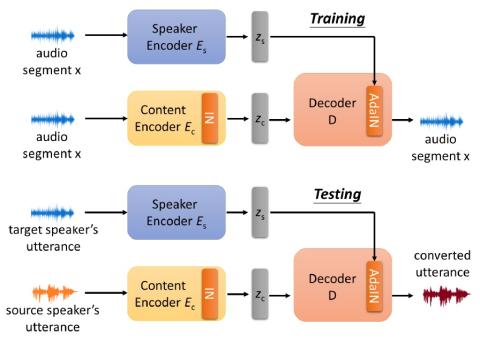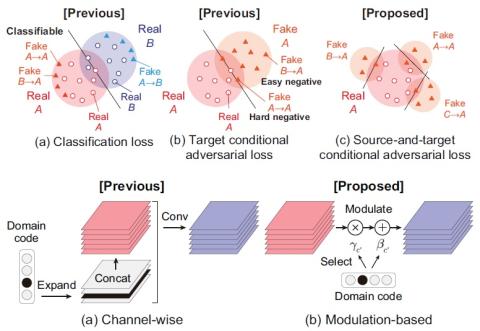
Полууправляемое преобразование голоса с амортизированным вариационным выводом
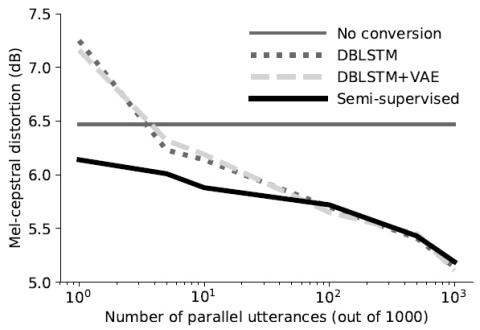
В этой работе мы представляем полууправляемый подход к задаче преобразования голоса, при котором речь от исходного диктора преобразуется в речь от целевого диктора. Предлагаемый метод использует как параллельные, так и непараллельные высказывания от исходного и целевого одновременно во время обучения. Этот подход может быть использован для расширения существующих систем параллельного преобразования речевых данных таким образом, чтобы их можно было обучать с полуавтоматическим контролем. Мы показываем, что включение режима полунаблюдения повышает эффективность преобразования голоса по сравнению...