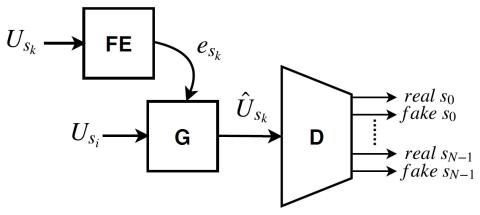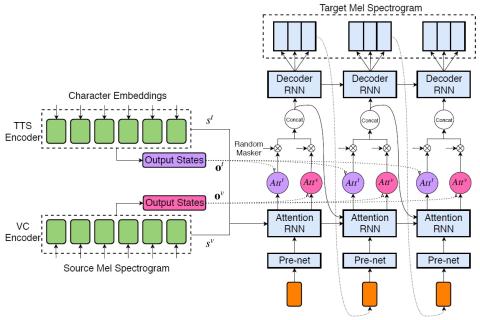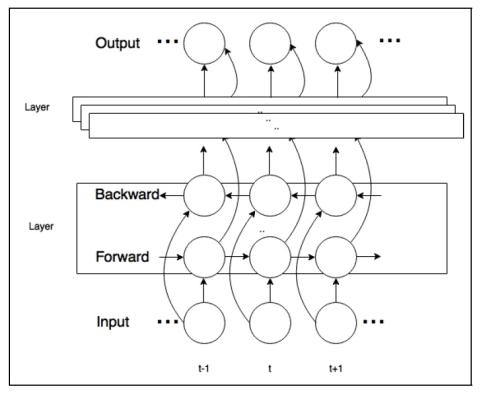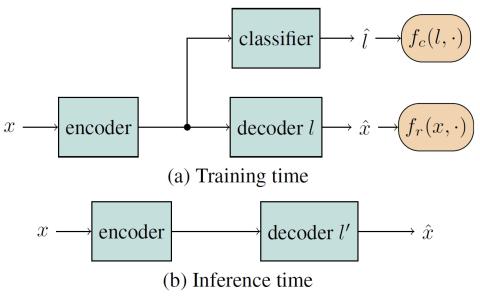
Автокодеры с противоборствующим обучением для преобразования голоса без использования параллельных данных
Мы представляем метод преобразования голоса между несколькими говорящими. Наш метод основан на обучении нескольких путей автоэнкодирования, где имеется один кодер, независимый от говорящего, и несколько декодеров, зависящих от говорящего. Автоэнкодеры обучаются с добавлением потерь при столкновении, которые обеспечиваются вспомогательным классификатором, чтобы выходные данные кодера были независимыми от диктора. Обучение модели проходит без контроля в том смысле, что для этого не требуется собирать одинаковые высказывания от говорящих и не требуется время на согласование фонем. Благодаря испол...