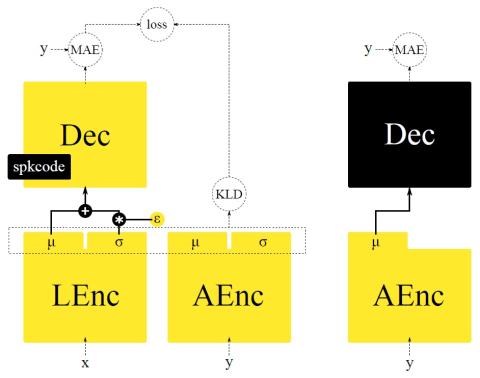
Преобразование голоса и текста в речь - это две задачи, которые преследуют схожую цель: генерировать речь с помощью целевого голоса. Однако, как правило, они разрабатываются независимо друг от друга в рамках совершенно разных платформ. В этой статье мы предлагаем методологию начальной загрузки системы преобразования голоса из предварительно подготовленной модели преобразования текста в речь, адаптируемой к диктору, и объединяем методы, а также интерпретации этих двух задач. Более того, благодаря переносу большого объема данных на этап обучения модели преобразования текста в речь, наша система преобразования голоса может быть построена с использованием небольшого объема речевых данных целевого носителя. Это также открывает возможность использования речи на иностранном языке, который не используется при построении системы. Наши субъективные оценки показывают, что предлагаемый фреймворк способен не только обеспечить конкурентоспособность в стандартном внутриязыковом сценарии, но и адаптировать и преобразовывать речевые высказывания на незнакомом языке.
Вывод
В этой статье мы представили методологию для начальной загрузки системы преобразования голоса из предварительно подготовленной модели преобразования текста в речь, адаптируемой к диктору. Передав знания, полученные ранее с помощью модели преобразования текста в речь, мы смогли значительно снизить требования к данным для построения системы преобразования голоса. Это, в свою очередь, позволяет системе работать на невидимом языке с низким потреблением ресурсов. Субъективные результаты показывают, что наша система преобразования голоса обеспечивает конкурентоспособную производительность по сравнению с существующими методами. Более того, он также может быть использован для преобразования речи на разных языках и адаптации говорящего на разных языках. Хотя производительность в этих сценариях с невидимым языком не так высока, все эксперименты в этой работе проводились с учетом минимальных доступных ресурсов. Наша будущая работа включает в себя использование доступных дополнительных ресурсов, таких как многоязычный корпус, для дальнейшего повышения надежности системы преобразования голоса.