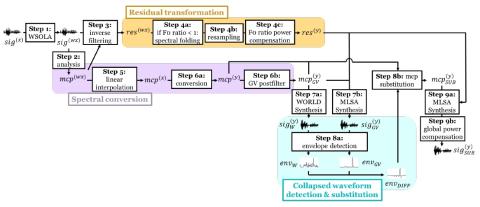
Мы представляем прямую модификацию формы сигнала для преобразования голоса на основе дифференциала спектра (DIFFVC), которая может быть непосредственно применена в качестве модуля генерации формы сигнала к моделям преобразования голоса. Недавно предложенный DIFFVC позволяет избежать использования вокодера, сохраняя при этом богатые спектральные характеристики, что позволяет генерировать преобразованный голос высокого качества. Для применения платформы DIFFVC необходимо предварительно обучить модель, которая может оценивать спектральную разницу по преобразованной входной речи F0. Это требование накладывает ряд ограничений, включая ограничение на параллельное обучение модели оценки и необходимость дополнительного обучения для каждой пары преобразований, что делает DIFFVC негибким. Исходя из вышеуказанных соображений, мы предлагаем новую структуру DIFFVC, основанную на преобразовании F0 в остаточной области. Благодаря выполнению обратной фильтрации входного сигнала с последующей синтезирующей фильтрацией преобразованного остаточного сигнала F0 с использованием непосредственно преобразованных спектральных характеристик, модель спектрального преобразования не нуждается в переобучении или способна предсказывать спектральную разницу. Мы описываем несколько деталей, о которых необходимо позаботиться в рамках этой модификации, и, применяя предложенный нами метод к непараллельной модели спектрального преобразования на основе вариационного автоэнкодера (VAE), мы демонстрируем, что эта структура может быть обобщена на любую модель спектрального преобразования, а экспериментальные оценки показывают, что она может превосходить базовую структуру, процесс генерации формы сигнала которой осуществляется вокодером.
Выводы и будущая работа
В этой статье мы представили обобщение фреймворка DIFFVC, чтобы сделать его применимым к общим моделям преобразования голоса. Предлагаемый метод основан на преобразовании F0 в остаточной области, так что фильтрация синтеза выполняется непосредственно с использованием преобразованных спектральных характеристик, что устраняет необходимость в том, чтобы модель преобразования могла предсказывать спектральную разницу, что делает весь процесс свободным от параллельного обучения данным. Мы также представили несколько методов, используемых в этой системе, включая 1) альтернативу для восстановления высокочастотной составляющей на основе нулевого заполнения, 2) обнаружение свернутой формы сигнала и соответствующую замену характеристик, и 3) компенсацию мощности за счет повторной дискретизации. Результаты экспериментов подтвердили, что при применении к непараллельной модели преобразования голоса на основе VAE наш метод превзошел аналогичную модель, использующую обычный вокодер, с точки зрения точности преобразования, при этом естественность была на одном уровне.
Исследование эффективности отдельных компонентов, предложенных в этой работе, а также более глубокий анализ результатов экспериментов будут иметь первостепенное значение для будущей работы. Мы также планируем применить нашу концепцию к другим моделям непараллельного преобразования голоса для дальнейшей проверки эффективности. Разработка надежного средства выделения спектральных характеристик с частотным диапазоном может помочь решить различные проблемы, рассмотренные в разделе 4.3, что станет еще одной важной работой в будущем.