В данной статье оценивается эффективность преобразования голоса на основе Cycle-GAN для четырех систем идентификации говорящих (SID) и автоматизированной системы распознавания речи (ASR) для различных целей. Аудиосэмплы, преобразованные с помощью модели voice converter, классифицируются сторонними системами как целевые с точностью до 46% и входят в топ-1 среди более чем 250 говорящих. Этот обнадеживающий результат в имитации целевых стилей побудил нас исследовать, можно ли использовать преобразованные (синтетические) образцы для улучшения обучения ASR. К сожалению, добавление синтетических данных в обучающий набор ASR лишь незначительно повышает частоту ошибок в словах и символах. Наши результаты показывают, что, несмотря на то, что модели голосовых преобразователей могут успешно имитировать стиль говорящих на целевом уровне, измеряемый системами SID, улучшение обучения ASR с использованием синтетических данных из систем голосовых преобразователей требует дальнейших исследований, чтобы установить его эффективность.
Обсуждение
В этой статье мы сообщаем, что модель преобразования голоса на основе Cycle-GAN может генерировать аудиофайлы, которые классифицируются четырьмя различными автоматизированными моделями SID как предназначенные для целевого диктора, с точностью до 46%. Существуют значительные различия между побочными моделями, причем модели, основанные на глубоком обучении, имеют более высокие показатели предполагаемой целевой классификации, чем модели, основанные на i-векторе.
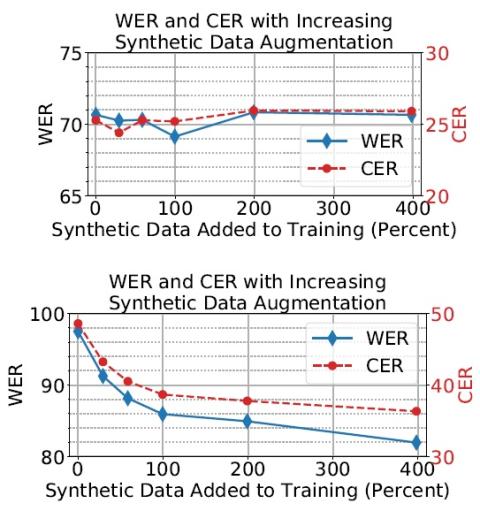
Кроме того, мы исследуем, можно ли использовать высокую имитационную способность стиля, оцененную SID systems, для повышения частоты ошибок при обучении ASR. Наши результаты демонстрируют незначительное улучшение показателей WER / CER при использовании модели преобразования голоса для увеличения набора обучающих данных ASR. Этот последний результат согласуется с методами расширения на основе GAN, используемыми в области компьютерного зрения, и демонстрирует необходимость дальнейших исследований, прежде чем модели голосовых преобразователей можно будет использовать для облегчения обучения в последующих задачах, таких как ASR. Одним из будущих направлений является дальнейшее повышение качества преобразования голоса за счет использования архитектуры GAN, которая может имитировать стили в мельчайших деталях (Karras et al., 2018). Также следует изучить возможность использования нейронного вокодера для восстановления необработанных звуковых сигналов из преобразованных спектрограмм для улучшения качества преобразований.