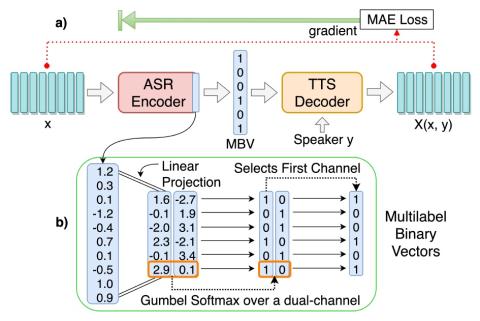
Мы представляем неконтролируемую сквозную схему обучения, в которой мы извлекаем отдельные подсловные единицы из речи без использования каких-либо меток. Отдельные подсловные единицы запоминаются с помощью настройки восстановления автоэнкодера ASR-TTS, при которой ASR-кодер обучается обнаруживать набор общих языковых единиц для различных носителей языка, а TTS-декодер обучается проецировать обнаруженные единицы обратно в заданную речь. Мы предлагаем метод дискретного кодирования, многометровые двоичные векторы (MBV), чтобы сделать автоэнкодер ASR-TTS дифференцируемым. Мы обнаружили, что предложенный метод кодирования обеспечивает автоматическое извлечение речевого контента из стиля говорящего и достаточен для полного охвата лингвистического контента на данном языке. Таким образом, TTS-декодер может синтезировать речь с тем же содержанием, что и на входе ASR-кодера, но с другими характеристиками говорящего, что обеспечивает преобразование голоса. Мы еще больше улучшаем качество преобразования голоса, используя состязательное обучение, в ходе которого мы обучаем TTS-патчер, который увеличивает производительность TTS-декодера. Объективные и субъективные оценки показывают, что предложенный подход обеспечивает отличные результаты преобразования голоса, поскольку устраняет идентификацию говорящего, сохраняя при этом содержание речи. В конкурсе ZeroSpeech 2019 мы добились выдающихся результатов с точки зрения низкого битрейта.
Выводы
Мы предложили использовать бинарные векторы с несколькими метками для представления содержания человеческой речи, поскольку их дискретный характер обеспечивает надежное извлечение информации, не зависящей от говорящего. Мы показали, что эти дискретные единицы естественным образом обладают способностью разделять содержание и стиль речи, что делает их чрезвычайно подходящими для задач преобразования голоса. Кроме того, мы показали, что эти дискретные устройства действительно обеспечивают лучшую разборчивость стиля, чем обычные настройки, и, наконец, мы смогли улучшить результаты преобразования голоса за счет добавления остаточных дополненных сигналов.