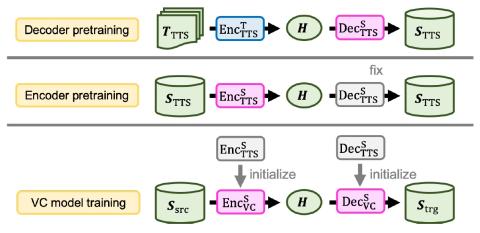
Мы представляем новую модель преобразования голоса из последовательности в последовательность (seq2seq), основанную на архитектуре Transformer с предварительной подготовкой текста в речь. Модели преобразования голоса Seq2seq привлекательны благодаря своей способности преобразовывать просодию. В то время как модели seq2seq, основанные на рекуррентных нейронных сетях (RNNS) и сверточных нейронных сетях (CNNS), успешно применяются для преобразования голоса, использование сети Transformer, которая показала многообещающие результаты в различных задачах обработки речи, еще не исследовалось. Тем не менее, их ресурсоемкость и неправильное произношение преобразованной речи делают модели seq2seq далекими от практичности. С этой целью мы предлагаем простую, но эффективную методику предварительной подготовки для передачи знаний из изученных моделей преобразования текста в речь, которые выигрывают от крупномасштабных и легкодоступных корпусов преобразования текста в речь. Модели преобразования голоса, инициализированные с помощью таких предварительно подготовленных параметров модели, способны генерировать эффективные скрытые представления для получения высококачественной и разборчивой преобразованной речи. Результаты экспериментов показывают, что такая схема предварительной подготовки может способствовать эффективному использованию данных и превосходить модель преобразования голоса seq2seq на основе RNN с точки зрения разборчивости, естественности и сходства.
Вывод
В этой работе мы успешно применили структуру Transformer для преобразования голоса в seq2seq. Кроме того, для решения проблем, связанных с эффективностью передачи данных и неправильным произношением при преобразовании голоса в seq2seq, мы предложили перенос знаний из легкодоступных крупномасштабных корпусов данных для преобразования текста в речь путем инициализации моделей преобразования голоса с помощью предварительно подготовленных моделей преобразования текста в речь. Двухэтапная стратегия обучения, которая предварительно тренирует декодер и кодировщик, впоследствии гарантирует, что будут сгенерированы и полностью использованы детализированные промежуточные представления. Объективные и субъективные оценки показали, что наша схема предварительной подготовки может значительно улучшить разборчивость речи, и она значительно превосходит базовый уровень преобразования голоса seq2seq на основе RNN. Даже при ограниченном количестве обучающих данных наша система может быть успешно обучена без существенного снижения производительности. В будущем мы планируем более систематически изучать эффективность архитектуры Transformer по сравнению с моделями, основанными на RNN. Распространение наших методов предварительной подготовки на более гибкие условия обучения, такие как непараллельное обучение, также является важной задачей на будущее.