Преобразование голоса - это задача преобразовать голос человека в другой стиль, сохранив при этом лингвистическое содержание. Предыдущее современное решение по преобразованию голоса основано на модели "последовательность в последовательность" (seq2seq), которая могла привести к искажению лингвистической информации. Была предпринята попытка преодолеть это с помощью текстового контроля, который требует явного выравнивания, что лишает преимущества использования модели seq2seq. В этой статье представлен голосовой конвертер, использующий многозадачное обучение с преобразованием текста в речь. Пространство встраивания преобразования текста в речь на основе seq2seq содержит обширную информацию о тексте. Роль декодера текста в речь заключается в преобразовании встроенного пространства в речь, что аналогично преобразованию голоса. В предлагаемой модели вся сеть обучена минимизировать потери при преобразовании голоса и текста в речь. Ожидается, что преобразование голоса позволит получить больше лингвистической информации и сохранить стабильность обучения за счет многозадачного обучения. Эксперименты по преобразованию голоса были проведены на наборе данных эмоциональной текстовой речи корейцев мужского пола, и было показано, что многозадачное обучение помогает сохранить лингвистическое содержание при преобразовании голоса.
Вывод
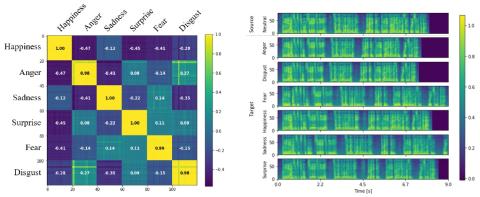
В этой статье мы представили эмоциональное преобразование голоса с использованием многозадачного обучения с преобразованием текста в речь. Несмотря на многочисленные исследования по преобразованию голоса, эффективность преобразования голоса недостаточна с точки зрения сохранения лингвистической информации, эмоционального преобразования голоса и преобразования "многие ко многим". В отличие от предыдущих методов, лингвистическое содержание преобразования голоса сохраняется благодаря многозадачному обучению с помощью преобразования текста в речь. Одна модель обучается оптимизации как при преобразовании голоса, так и текста в речь, а пространство встраивания обучается захвату лингвистической информации с помощью преобразования текста в речь. Результат показывает, что использование многозадачного обучения значительно снижает WER, и субъективная оценка также подтверждает это. Для преобразования эмоционального голоса мы собрали корейскую параллельную базу данных по семи различным эмоциям, и модель была обучена генерировать речь в зависимости от введенного эталонного стиля. Кроме того, style encoder предназначен для извлечения информации о стиле при удалении лингвистической информации. Без явного ввода метки эмоций style encoder успешно распознает эмоции.
Это исследование может быть распространено на многие другие направления. Во-первых, мы только показываем возможность преобразования текста в речь в голос, но преобразование текста в речь также может быть улучшено с помощью преобразования голоса, поскольку в некоторых языках существует очень нелинейная связь между текстом и его произношением. Во-вторых, кодировщик содержимого обучен извлекать только лингвистическую информацию, что может быть расширено для улучшения распознавания речи. В-третьих, можно добавить более явные потери, такие как потери из-за конкуренции доменов, чтобы свести к минимуму разницу между внедрением преобразования голоса и текста в речь в лингвистическом пространстве.