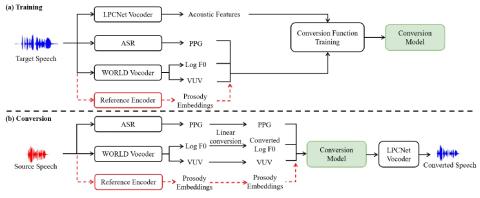
В типичной системе преобразования голоса в предыдущих работах использовались различные акустические характеристики (например, высота тона, озвученный/невокализованный флаг, непериодичность) исходной речи для управления просодией генерируемого сигнала. Однако просодия зависит от многих факторов, таких как интонация, ударение и ритм. Точное описание просодии с помощью акустических характеристик - непростая задача. Чтобы решить эту проблему, мы предлагаем встроенные функции просодии для моделирования просодии. Эти вставки извлекаются из исходной речи неконтролируемым образом. Мы проводим эксперименты с нашим корпусом мандаринского языка, записанным профессиональными дикторами. Результаты экспериментов показывают, что предлагаемый метод позволяет тонко контролировать просодию. В сложных ситуациях (например, когда исходной речью является пение песни) предлагаемый нами метод также может дать многообещающие результаты.
Выводы
В этой статье мы предлагаем платформу преобразования голоса, основанную на внедрении prosody и LPCNet. Внедрение prosody позволяет осуществлять детальный контроль над просодией сгенерированной речи. Pcnet может синтезировать речь с качеством, близким к естественному, при работе в режиме реального времени на стандартном процессоре. Субъективные оценки показывают, что предлагаемый метод позволяет добиться как высокой естественности, так и высокой схожести с диктором в сложных ситуациях, например, когда исходной речью является пение песни.