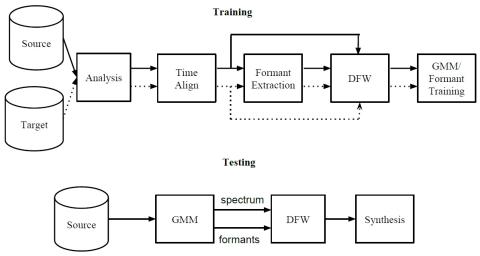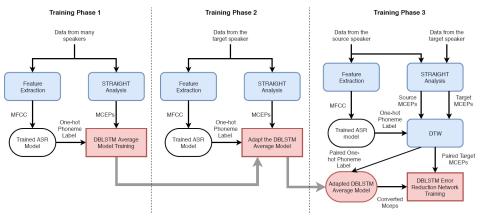
Сеть уменьшения ошибок для преобразования голоса на основе DBLSTM
На данный момент многие подходы к глубокому обучению для преобразования голоса позволяют получать речь хорошего качества, используя большое количество обучающих данных. В этой статье представлена платформа преобразования голоса на основе глубокой двунаправленной долговременной памяти (DBLSTM), которая может работать с ограниченным количеством обучающих данных. Мы предлагаем реализовать усредненную модель на основе DBLSTM, которая обучается на данных от многих дикторов. Затем мы предлагаем выполнить адаптацию с ограниченным количеством целевых данных. И последнее, но не менее важное: мы предлаг...