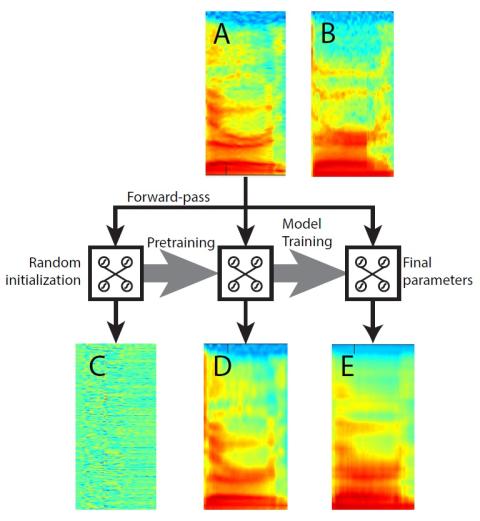
За последнее десятилетие методы преобразования голоса быстро развивались. Исследования показали, что характеристики диктора определяются спектральными характеристиками, а также различными просодическими особенностями. Большинство существующих методов преобразования фокусируются на спектральной характеристике, поскольку она непосредственно отражает тембровые характеристики, в то время как некоторые методы преобразования сосредоточены только на просодической характеристике, представленной основной частотой. В этой статье предлагается комплексная структура, использующая глубокие нейронные сети для преобразования как тембровых, так и просодических характеристик. Тембровая характеристика представлена спектральной характеристикой с высоким разрешением. Просодические характеристики включают F0, интенсивность и длительность. Хорошо известно, что DNN полезен в качестве инструмента для моделирования многомерных характеристик. В этой работе мы показываем, что DNN, инициализированный с помощью предложенного нами предварительного обучения автоэнкодера, дает высококачественные модели преобразования DNN. Это предварительное обучение разработано специально для преобразования голоса и использует автоэнкодер для получения общей спектральной формы исходной речи. Кроме того, наш фреймворк использует сегментарные модели DNN для отслеживания эволюции просодических функций с течением времени. Чтобы восстановить преобразованный голос, спектральный признак, полученный с помощью модели DNN, объединяется с тремя просодическими признаками, полученными с помощью сегментарных моделей DNN. Наши экспериментальные результаты показывают, что применение как просодических, так и спектральных характеристик с высоким разрешением приводит к качественному преобразованию голоса, измеряемому с помощью объективной оценки и субъективных тестов на прослушивание.
Выводы
В этой статье представлена комплексная система преобразования голоса, в которой спектры высокого разрешения, F0, интенсивность и длительность сегмента преобразуются с использованием DNN. Объективные и субъективные оценки показывают возможности моделирования многомерных полных спектральных и просодических сегментов. Показано, что предложенная предварительная подготовка автоэнкодера к преобразованию голоса эффективно инициализирует параметры модели и приводит к точной спектральной оценке. Результирующая модель спектрального преобразования с предлагаемым нами предварительным обучением достигает показателей, сравнимых по сходству и качеству с другой современной системой преобразования голоса, прошедшей предварительную подготовку.
В обычных работах по преобразованию голоса просодические особенности обычно не моделируются. Зная, что человек манипулирует просодией на различных уровнях, а не на основе локального кадра, мы внедрили сегментное моделирование и преобразование для F0, интенсивности и длительности, не увеличивая объем обучающих данных для типичных сценариев преобразования голоса. Наши экспериментальные результаты показали, что полученная в результате преобразованный голос во многом похож на голос целевого диктора. На протяжении всей этой работы создается приемлемая структура преобразования голоса, в которой множество функций преобразуются акустически, и будущие исследования способов моделирования и преобразования тембровых и просодических характеристик по-прежнему заставляют задуматься. Чтобы лучше понять эффективность преобразования интенсивности и длительности, мы планируем оценить влияние изменения интенсивности и длительности на преобразование голоса с помощью более интенсивных психоакустических экспериментов.