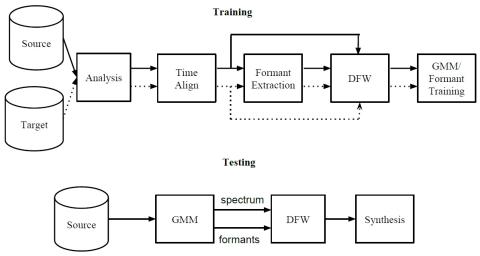
В этом исследовании мы исследуем решение, позволяющее уменьшить влияние проблемы "один ко многим" при преобразовании голоса. Проблема "один ко многим" при преобразовании голоса возникает, когда два очень похожих речевых сегмента исходного диктора имеют соответствующие речевые сегменты целевого диктора, которые не похожи друг на друга. В результате функция отображения обычно сглаживает сгенерированные объекты, чтобы они были похожи на оба целевых речевых сегмента. В этом исследовании мы предлагаем выровнять расположение формантов пар исходных и целевых кадров, используя динамическое искажение частоты, чтобы снизить сложность. После преобразования голоса применяется еще одно динамическое искажение частоты, чтобы устранить эффект выравнивания расположения формант во время обучения. Субъективные эксперименты показали, что предложенный подход значительно улучшает качество речи.
Вывод
В этой статье мы исследовали решение, позволяющее уменьшить влияние проблемы "один ко многим" при преобразовании голоса. Мы предложили выровнять формантное расположение пар исходных и целевых кадров, используя динамическое искажение частоты, чтобы снизить сложность. Наконец, после преобразования дополнительно применяется динамическое искажение частоты, чтобы устранить эффект выравнивания расположения формант. Мы смогли продемонстрировать значительное улучшение качества преобразования голоса. Здесь возникают две проблемы. Проблема заключается в использовании DFW непосредственно в области логарифмического спектра, что может привести к искажению спектров, особенно при наличии ошибки форманты. Для устранения этой проблемы может оказаться полезным использование других методов искажения, таких как сдвиг полюсов. Другой, более важной проблемой является неизбежное несовпадение оценок формант. Для решения этой проблемы в экспериментальных целях можно использовать значения формант, скорректированные вручную, чтобы увидеть реальный эффект предлагаемого подхода с использованием информации об истинности формант.