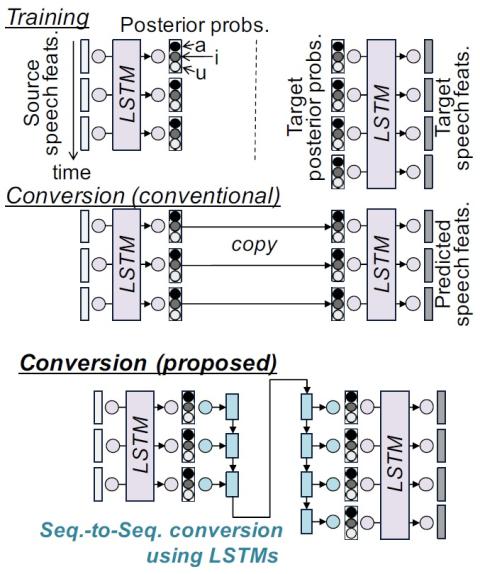
Предлагается преобразование голоса с использованием последовательного изучения апостериорных вероятностей контекста. Традиционное преобразование голоса с использованием апостериорных вероятностей общего контекста предсказывает параметры целевой речи на основе апостериорных вероятностей контекста, оцененных на основе параметров исходной речи. Хотя обычное преобразование голоса может быть построено на основе непараллельных данных, трудно преобразовать индивидуальность говорящего, такую как фонетические свойства и скорость речи, содержащиеся в апостериорных вероятностях, поскольку исходные апостериорные вероятности непосредственно используются для прогнозирования параметров целевой речи. В этой работе мы предполагаем, что обучающие данные частично включают в себя параллельные речевые данные, и предлагаем последовательное обучение между исходной и целевой апостериорными вероятностями. Модели преобразования выполняют нелинейное преобразование переменной длины из исходной вероятностной последовательности в целевую. Далее мы предлагаем алгоритм совместного обучения модулей. В отличие от обычного преобразования голоса, при котором отдельно обучаются распознаванию речи, оценивающему апостериорные вероятности, и синтезу речи, предсказывающему параметры целевой речи, предлагаемый нами метод совместно обучает эти модули вместе с предлагаемыми модулями преобразования вероятности. Экспериментальные результаты показывают, что наш подход превосходит традиционное преобразование голоса.
Вывод
В этой статье мы предложили преобразование голоса с использованием последовательного изучения апостериорных вероятностей контекста. Поскольку обычное преобразование голоса напрямую использует апостериорные вероятности исходной речи для прогнозирования целевой речи, трудно преобразовать индивидуальность говорящего, включенную в апостериорные вероятности. Чтобы решить эту проблему, мы построили модели преобразования последовательности в последовательность, которые преобразуют исходную контекстную апостериорную вероятностную последовательность в целевую. Кроме того, мы предложили совместные обучающие алгоритмы для распознавания речи, синтеза речи и апостериорного преобразования вероятности. Результаты экспериментов показали, что (1) предложенные алгоритмы превзошли обычное преобразование голоса по сходству с диктором, и (2) совместное обучение распознаванию и синтезу превзошло обычное преобразование голоса как по сходству с диктором, так и по качеству речи. В качестве будущей работы мы рассмотрим, как определить длину кадра преобразованной апостериорной вероятностной последовательности.