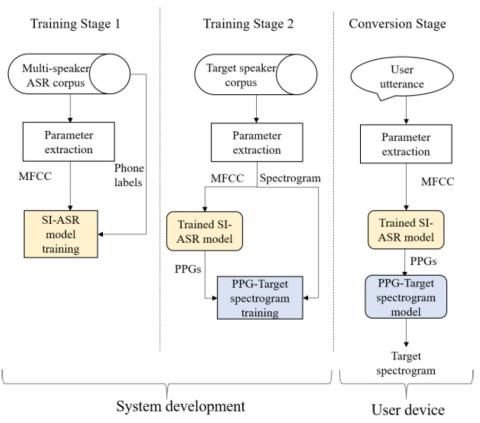
Недавние работы по использованию фонетических апостериограмм (PPGs) для непараллельного преобразования голоса значительно повысили удобство использования преобразования голоса, поскольку исходные и целевые базы данных больше не требуются для сопоставления содержимого. В этом подходе PPGs используются в качестве лингвистического моста между исходными и целевыми характеристиками говорящего. Однако это непараллельное преобразование голоса на основе PPG имеет некоторое ограничение, заключающееся в том, что оно требует двух каскадных сетей во время преобразования, что делает его менее подходящим для приложений реального времени и уязвимым для разборчивости исходной динамики внятности на этапе преобразования. Чтобы устранить это ограничение, мы предлагаем новый метод непараллельного преобразования голоса, который использует единую нейронную сеть для прямого сопоставления параметров голоса от источника к цели. При такой единой сетевой структуре предлагаемый подход позволяет сократить как время преобразования, так и количество сетевых параметров, что может быть особенно важным фактором во встроенных средах или средах реального времени. Кроме того, он улучшает качество преобразования голоса, пропуская распознаватель телефона на этапе преобразования. Это может эффективно предотвратить возможную потерю фонетической информации, от которой страдает косвенный метод PPG. Эксперименты показывают, что наш подход сокращает количество сетевых параметров и время преобразования на 41,9% и 44,5% соответственно, улучшая сходство голоса по сравнению с оригинальным методом на основе PPG.
Выводы
В этой статье мы предлагаем новый подход к непараллельному преобразованию голоса, который использует единую сеть для сопоставления исходных и целевых объектов без использования PPGs на этапе преобразования. Благодаря такой простой архитектуре наш метод работает быстрее и требует меньшего объема памяти. Он также улучшил MCD, устранив потери информации, вызванные лингвистическим мостом на основе PPG. В экспериментах подтверждено, что предложенный метод сокращает время преобразования на 44,5% и количество параметров сети на 41,9% с максимальным улучшением MCD на 4,8% по сравнению с исходным уровнем.
Это сокращение времени преобразования предложенным методом может быть дополнительно достигнуто при развертывании в сочетании с сетевыми моделями меньшего размера и меньшего количества параметров.
По мере дальнейшей работы будет интересно провести сравнение производительности между предлагаемым подходом и методом параллельного преобразования голоса.