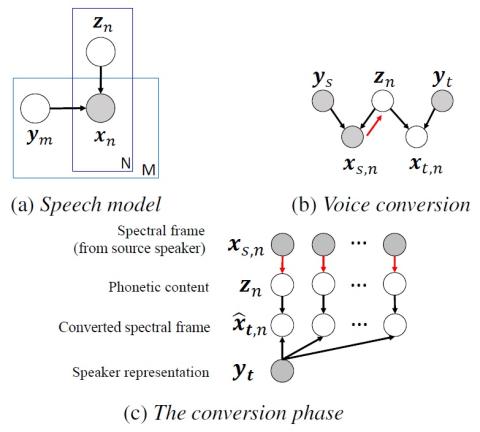
Создание системы преобразования голоса из непараллельных речевых массивов является сложной задачей, но очень ценной в реальных сценариях применения. В большинстве случаев говорящий на исходном и целевом языках не повторяет одни и те же тексты или даже может говорить на разных языках. В этом случае одним из возможных, хотя и косвенных, решений является построение порождающей модели для речи. Порождающие модели фокусируются на объяснении наблюдений с помощью скрытых переменных вместо изучения функции попарного преобразования, тем самым обходя требование выравнивания речевого фрейма. В этой статье мы предлагаем систему непараллельного преобразования голоса с вариативным автоэнкодированием генеративной состязательной сети Вассерштейна (VAW-GAN), которая явно учитывает цель преобразования голоса при построении речевой модели. Результаты экспериментов подтверждают способность нашей платформы создавать системы преобразования голоса на основе несогласованных данных и демонстрируют улучшенное качество преобразования.
Выводы
Мы представили систему преобразования голоса, которая способна напрямую интегрировать непараллельный критерий преобразования голоса в целевую функцию. Предложенная система VAW-GAN улучшает выходные данные, придавая им более реалистичные спектральные формы. Результаты экспериментов демонстрируют значительное улучшение производительности по сравнению с базовой системой.