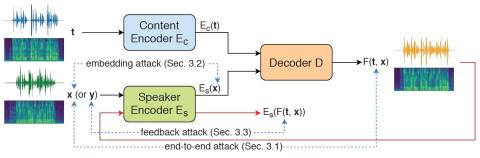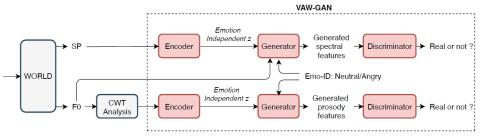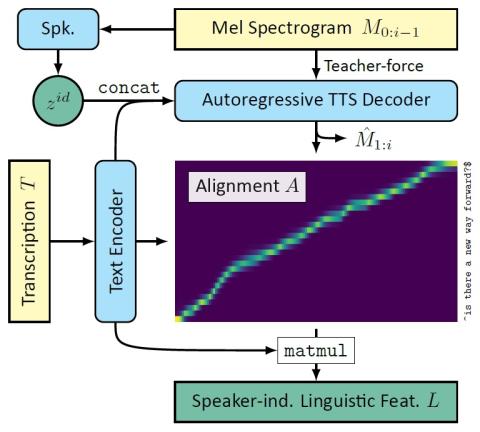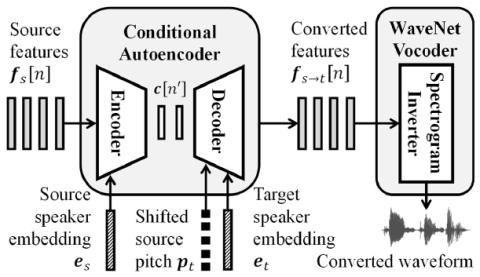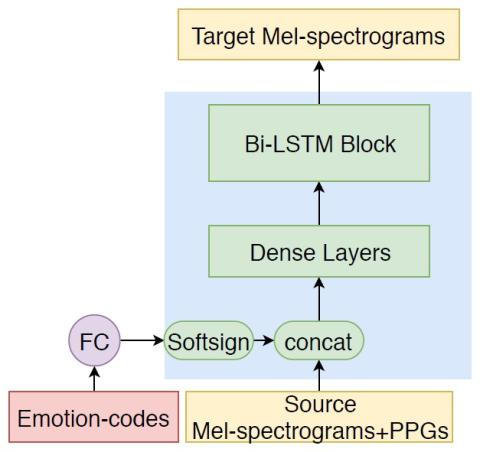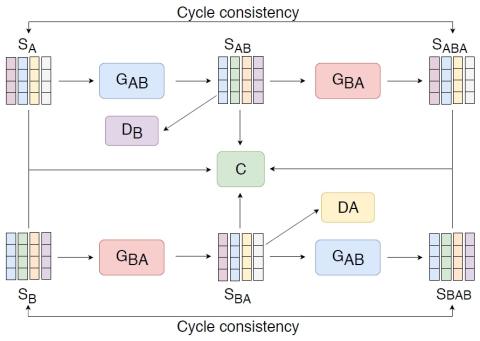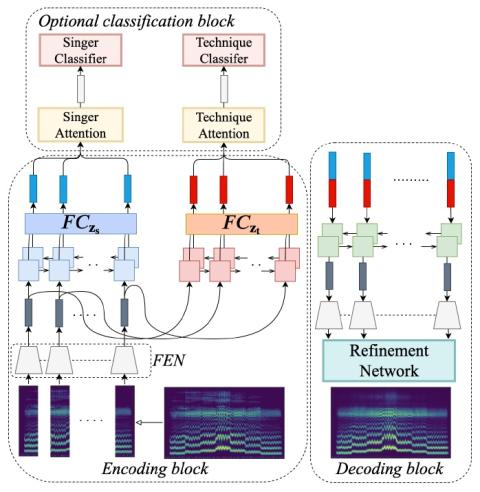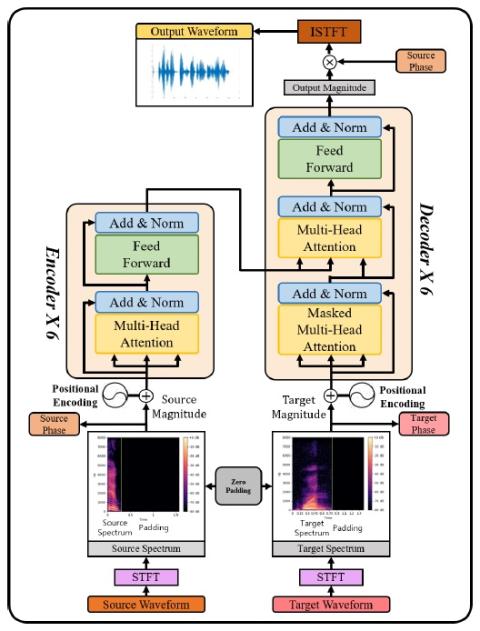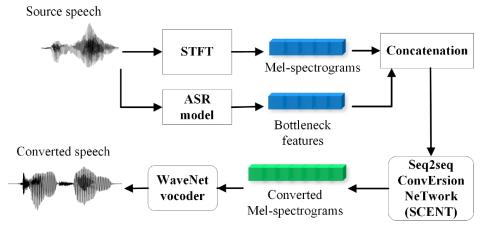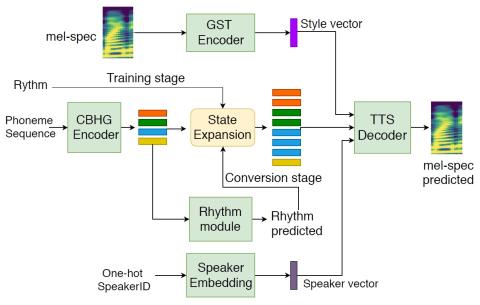
Передача исходного стиля при непараллельном преобразовании голоса
Методы преобразования голоса (VC) направлены на изменение идентичности говорящего высказывания при сохранении лежащей в его основе лингвистической информации. Большинство подходов преобразования голоса игнорируют моделирование стиля речи (например, эмоции и акцент), который может содержать факторы, намеренно добавленные говорящим, и должен быть сохранен во время преобразования. Это исследование предлагает основанный на последовательности непараллельный подход преобразования голоса, который имеет возможность передачи стиля речи от исходной речи к преобразованной речи путем явного моделирования....