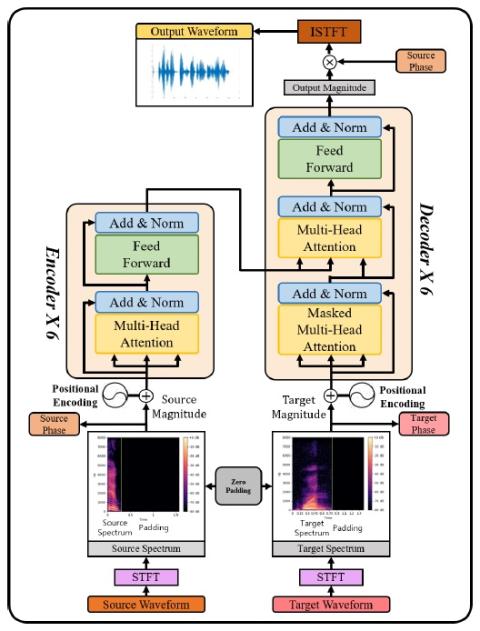
Подходы, основанные на использовании банка частотных фильтров Mel (MFB), имеют преимущество в изучении речи по сравнению с необработанным спектром, поскольку MFB имеет меньший размер элемента. Однако для создания генератора речи с использованием методов MFB требуется дополнительный вокодер, что требует огромных вычислительных затрат для процесса обучения. Дополнительная предварительная/постобработка, такая как MFB и вокодер, не обязательна для преобразования реальной человеческой речи в другие звуки. Можно использовать только необработанный спектр вместе с фазой, чтобы генерировать голоса другого стиля с четким произношением. В связи с этим мы предлагаем быстрый и эффективный подход к параллельному преобразованию реалистичных голосов с использованием необработанного спектра. Наша архитектура модели на основе трансформатора, в которой отсутствуют уровни CNN или RNN, продемонстрировала преимущество быстрого обучения и устранила ограничения, связанные с последовательным вычислением обычного RNN. В этой статье мы представляем метод сквозного преобразования голоса без вокодера с использованием сети transformer network. Представленная модель преобразования также может быть использована для адаптации говорящих для распознавания речи. Наш подход позволяет преобразовать исходный голос в целевой без использования MFB и вокодера. Мы можем получить адаптированный MFB для распознавания речи, умножив преобразованную амплитуду на фазу. Мы проводим наши эксперименты по преобразованию голоса на основе набора данных TIDIGITS, используя такие показатели, как естественность, сходство и четкость, со средним баллом по результатам опроса, соответственно.
Вывод
Мы предложили преобразование голоса с использованием механизма самонаблюдения на уровне необработанного спектра, в то время как традиционные методы используют вокодер на уровне MFB. Подходы, основанные на MFB, имеют преимущество в удобстве компьютерного обучения по сравнению с необработанным спектром. Однако для генераторов речи с использованием методов MFB требуется вокодер, который требует огромных вычислительных затрат для процесса обучения. С помощью вокодера можно добиться лучшего качества голоса при синтезе. Напротив, проблема сложности из-за дополнительных вычислений неизбежна. Дополнительная предварительная/постобработка, такая как MFB и вокодер, не обязательна для преобразования реальной человеческой речи в другие. В этой статье мы предложили метод сквозного преобразования голоса без вокодера с использованием быстрой и эффективной трансформаторной сети, которая может преобразовывать спектр параллельным образом. Преимущество получения результатов преобразования с использованием необработанного спектра без помощи повторяющегося вокодера состояло в том, что для получения результата использовалась исходная информация о фазе. Мы собрали 38 участников и провели оценку MOS на естественность, сходство и ясность преобразованной речи. По общему среднему показателю говорящих результаты нашего эксперимента получили 3:40 по естественности, 3:82 по сходству и 3:93 по ясности, соответственно. Наши результаты показали, что предложенный метод можно трансформировать с хорошей четкостью, сохраняя при этом надлежащую естественность и сходство.