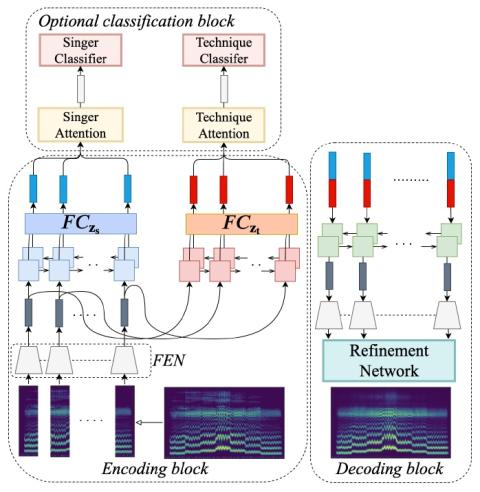
Мы предлагаем гибкую структуру, которая работает как с преобразованием голоса певца, так и с преобразованием вокальной техники певцов. Предлагаемая модель разработана на непараллельных корпусах, поддерживает преобразование "многие ко многим" и использует последние достижения вариационных автоэнкодеров. В нем используются отдельные кодеры для изучения скрытых представлений об индивидуальности певца и вокальной технике по отдельности, а для реконструкции используется совместный декодер. Преобразование осуществляется с помощью простой векторной арифметики в изученных скрытых пространствах. Как количественный анализ, так и визуализация преобразованных спектрограмм показывают, что наша модель способна разделить личность певца и вокальную технику и успешно выполнить преобразование этих атрибутов. Насколько нам известно, это первая совместная работа по преобразованию личности певца и вокальной техники на основе подхода глубокого обучения.
Заключение и дальнейшая работа
Мы предложили гибкую структуру, основанную на GMVAEs, для решения проблемы непараллельного взаимодействия "многие ко многим" в отношении идентичности певца и вокальной техники. Аудио-сэмплы доступны на https://reurl.cc/oD5vjQ. Анализ временной динамики скрытых переменных, а также учет зависимости между личностью певца и переменными вокальной техники будут в центре нашей будущей работы.