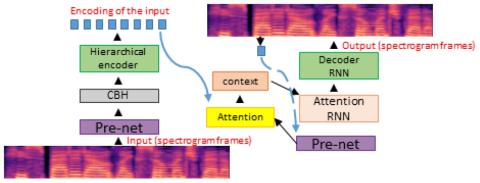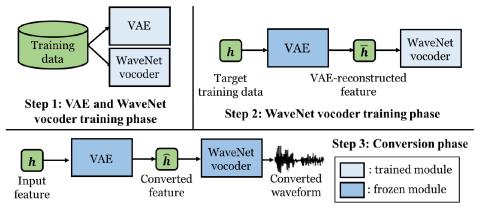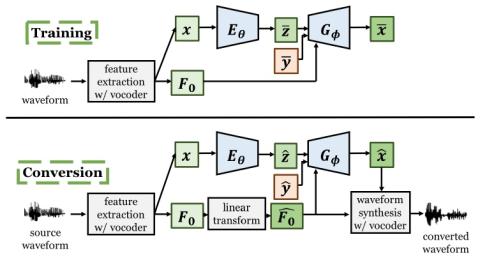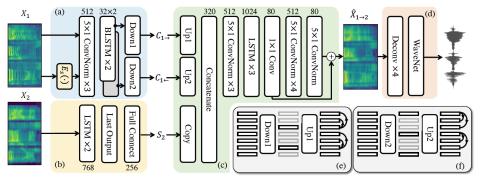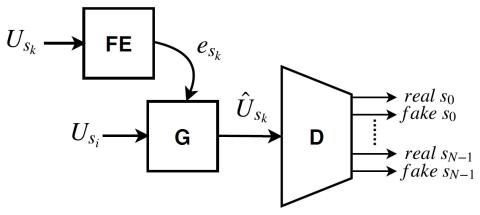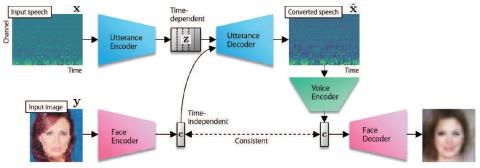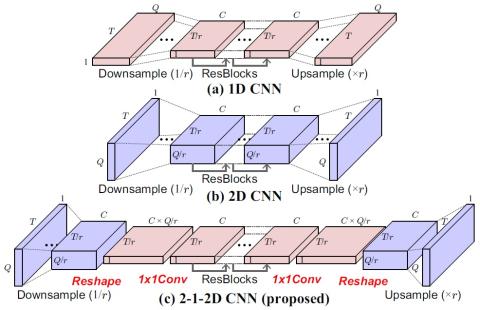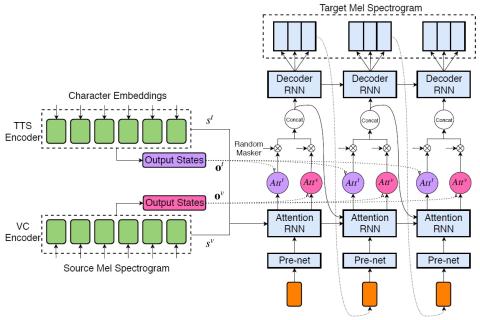
Обобщение прямой модификации формы сигнала на основе дифференциала спектра для преобразования голоса
Мы представляем прямую модификацию формы сигнала для преобразования голоса на основе дифференциала спектра (DIFFVC), которая может быть непосредственно применена в качестве модуля генерации формы сигнала к моделям преобразования голоса. Недавно предложенный DIFFVC позволяет избежать использования вокодера, сохраняя при этом богатые спектральные характеристики, что позволяет генерировать преобразованный голос высокого качества. Для применения платформы DIFFVC необходимо предварительно обучить модель, которая может оценивать спектральную разницу по преобразованной входной речи F0. Это требование...