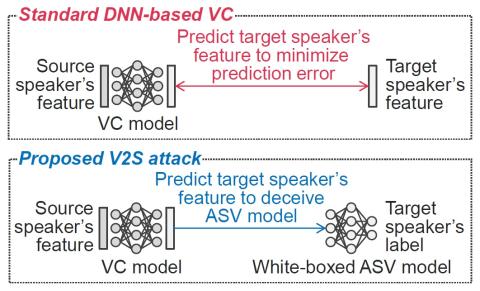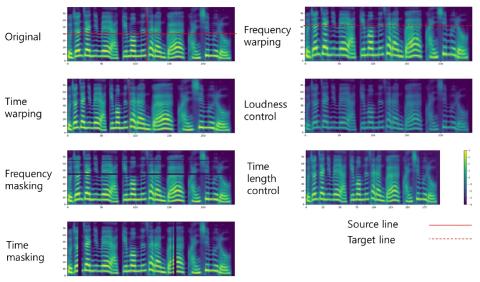
Расширение Mel-спектрограммы для преобразования голоса из последовательности в последовательность
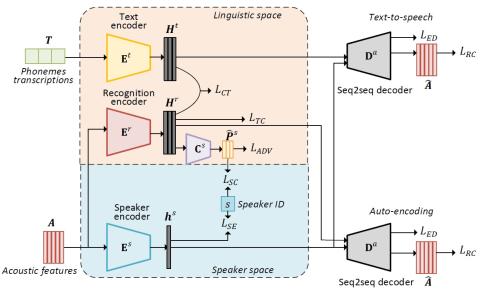
При обучении модели преобразования голоса от последовательности к последовательности нам необходимо решить проблему нехватки данных о количестве речевых кортежей, состоящих из одного и того же высказывания. В этом исследовании было проведено экспериментальное исследование влияния расширения Mel-спектрограммы на модель преобразования голоса от последовательности к последовательности. Для расширения Mel-спектрограммы мы применили правила, предложенные в Spec Augment. Кроме того, мы предлагаем новые правила для большего количества вариаций данных. Чтобы найти оптимальные гиперпараметры политик ус...