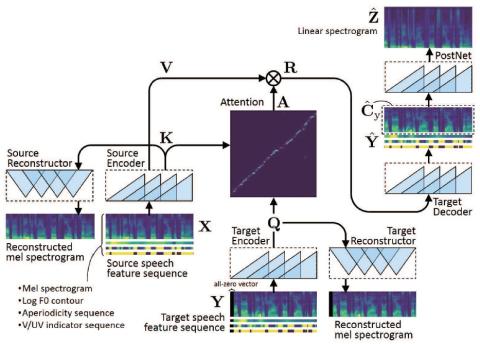
В этой статье предлагается метод преобразования голоса, основанный на полностью сверточном обучении от последовательности к последовательности (seq2seq). Настоящий метод, который мы называем "ConvS2S-VC", изучает соответствие между последовательностями речевых признаков источника и цели, используя полностью сверточную модель seq2seq с механизмом внимания. Из-за особенностей обучения seq2seq наш метод особенно примечателен тем, что он позволяет гибко преобразовывать не только характеристики голоса, но и контур высоты тона и продолжительность вводимой речи. Текущая модель состоит из шести сетей, а именно исходного и целевого кодеров, целевого декодера, исходного и целевого восстановителей и postnet, которые спроектированы с использованием расширенных сетей причинно-следственной свертки со стробируемыми линейными блоками. Эксперименты по субъективной оценке показали, что предложенный метод обеспечивает более высокое качество звука и сходство говорящих, чем базовый метод.
Выводы
В этой статье предлагается метод преобразования голоса, основанный на полностью сверточной модели seq2seq, которую мы называем “ConvS2S-VC”.
В будущем предстоит проделать большую работу. Хотя в качестве основы для настоящего эксперимента мы выбрали только один традиционный метод, мы планируем сравнить наш метод с другими современными методами. Кроме того, мы планируем провести более тщательные оценки, чтобы подтвердить правильность каждого из вариантов, которые мы сделали в отношении нашей модели, таких как архитектура сети, с управляемой потерей внимания или без нее, а также с механизмом сохранения контекста или без него, и сообщить о результатах в следующих статьях. Как и в случае с наиболее производительными системами, представленными на VCC 2018, мы заинтересованы во внедрении вокодера WaveNet в нашу систему вместо вокодера WORLD, чтобы добиться дальнейшего улучшения качества звука. Недавно мы также разрабатывали систему преобразования голоса, используя модель seq2seq на основе LSTM, параллельно с этой работой. Было бы интересно выяснить, какой из двух методов работает лучше в аналогичных условиях.