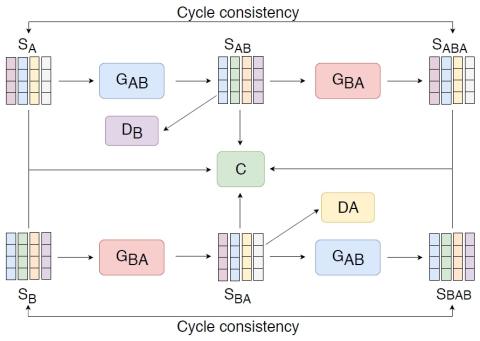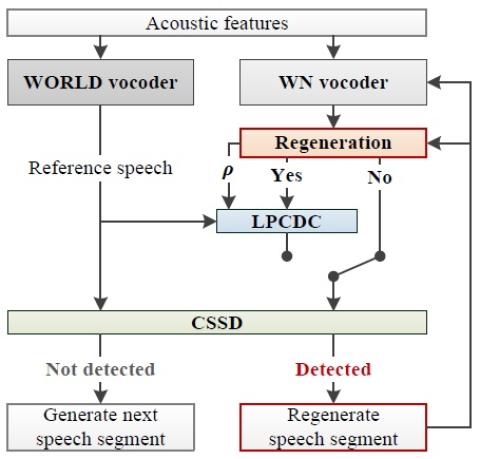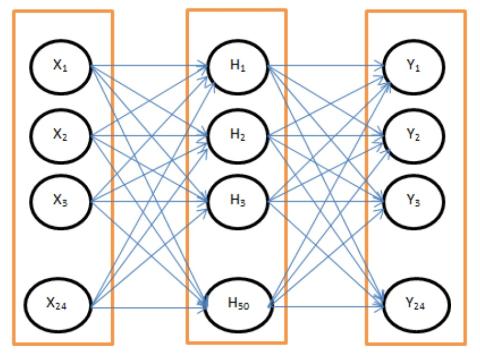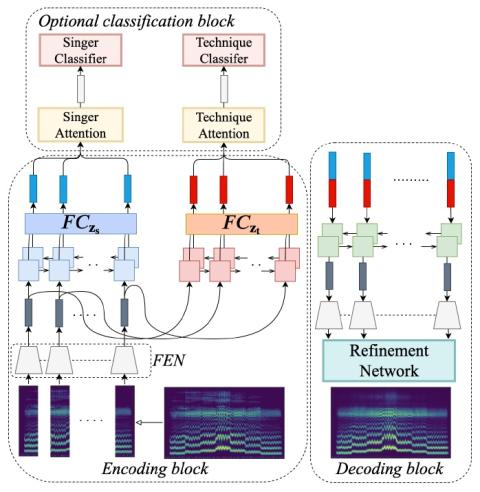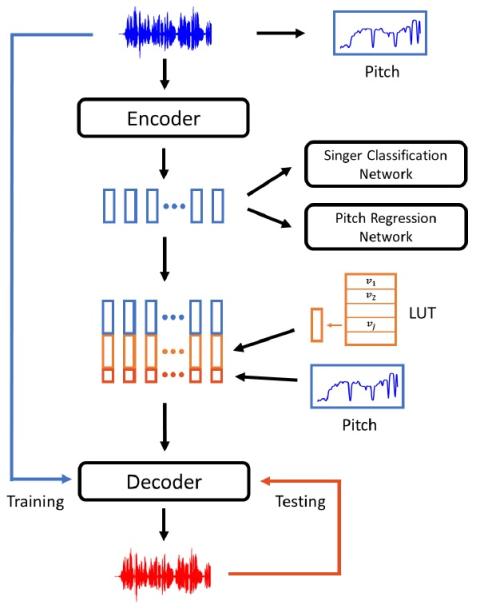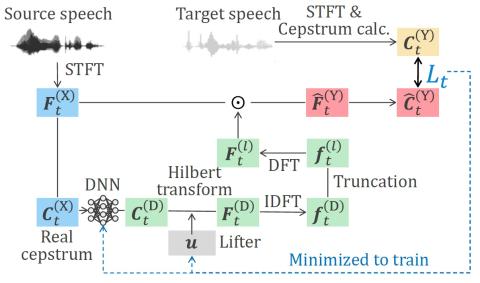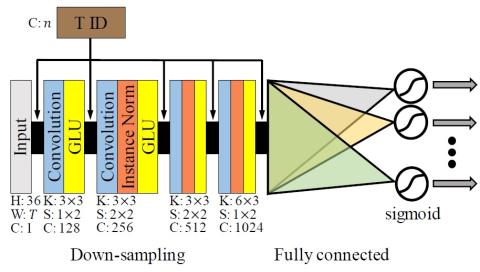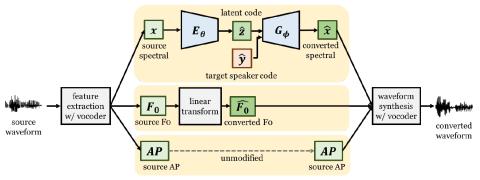
Multi-Target Emotional Voice Conversion With Neural Vocoders
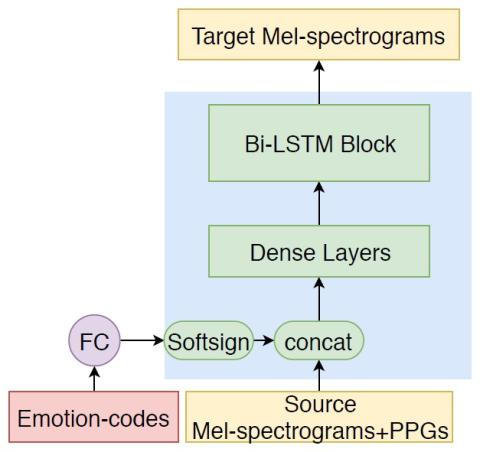
Emotional voice conversion (EVC) is one way to generate expressive synthetic speech. Previous approaches mainly focused on modeling one-to-one mapping, i.e., conversion from one emotional state to another emotional state, with Mel-cepstral vocoders. In this paper, we investigate building a multi-target EVC (MTEVC) architecture, which combines a deep bidirectional long-short term memory (DBLSTM)-based conversion model and a neural vocoder. Phonetic posteriorgrams (PPGs) containing rich linguistic information are incorporated into the conversion model as auxiliary input features, which boost the...